
Post anterior
Estructura SILO en SEO de URLsYa vamos por la versión 14.1 de Screaming Frog. No paran de sorprenderme y ayudar a muchísimos SEOs de todo el mundo. El crawler de escritorio por excelencia.
¿Por qué? Porque necesitamos vigilar cada uno de los aspectos de una página web, analizar y estudiar cada detalle para asegurar los pilares de la estrategia SEO de nuestro sitio web. Existe una gran variedad de herramientas para conseguirlo, aunque hay algunas que resaltan en este grupo debido a su eficiencia y eficacia. Screaming Frog es una de esas aplicaciones que debes tener en tu suite básica. A continuación, te daré toda la información sobre esta herramienta para que descubras el por qué.
¿Qué es y para qué sirve Screaming Frog?
Screaming Frog es un rastreador de webs, una herramienta fundamental para realizar análisis y auditar sitios web. Es una aplicación que se encuentra disponible tanto para Windows, como para Linux o Mac y nos permite realizar rastreos de enlaces en un sitio web.
Dentro de Screaming Frog podemos conseguir diferente información estructurada de una web: el título, la descripción, el estado de cada una de las URLs de la web y también las etiquetas del encabezado. Si se trata de una página web pequeña, podremos ver todos estos detalles en solo unos segundos, por otra parte, si se trata de un sitio web con numerosas páginas será un trabajo más prolongado, pero siempre igual de efectivo. Gracias a esta herramienta podemos mejorar la calidad de una página web y obtener información de mucha importancia.
Os dejo una demo rápida para que veáis la potencia de esta herramienta:
Aprende a descargarlo y configurarlo
Las oportunidades que nos ofrece Screaming Frog son muy variadas, por lo que el provecho que podemos sacar de esta herramienta depende de cómo manejemos estas opciones y el análisis que hagamos de los resultados. Pero bien, para comenzar debemos descargar la herramienta. Podemos conseguir una versión gratuita en la página web oficial de Screaming Frog que, aunque tendrá ciertas limitaciones, funciona muy bien para analizar páginas de proyectos pequeños.
Antes de seguir leyendo si no la tienes, accede y descárgala.
De igual forma, también encontraremos la versión de pago, que os aseguro que vale la pena si tenemos la posibilidad de adquirirla.
¡Vamos allá! Lo primero que debemos hacer es abrir la aplicación e introducir el dominio web en el lugar correspondiente, luego iniciamos la configuración del rastreo de esta página.

En la sección de configuración podremos introducir las opciones que nos interesan analizar, entre las opciones que esta herramienta nos permite rastrear tenemos: enlaces externos e internos, CSS, imágenes, Java Script, entre otros. Finalmente, cuando seleccionamos lo que queremos rastrear podemos pulsar el botón de Start y el proceso de rastreo iniciará, debemos esperar a que este finalice y luego extraer de los resultados la información que nos interesa. Cabe destacar que este procedimiento es sumamente básico, siempre podemos ahondar un poco más para conseguir información aún más detallada.
Primer acercamiento a un informe de screaming frog
Códigos de estado
En la pestaña de “Response Codes” podrás conseguir una lista de todas las direcciones de la web, acá podrás filtrar el resultado según el código de respuesta que arrojen. De este modo, podrás analizar todos los resultados que no cuenten con un buen código de respuesta y realizar los procesos necesarios para mejorar tu web.  Con los resultados de esta pestaña podrás comprobar si se encuentran bloqueadas por robots.txt las URLs que quieres. Así como también podrás comprobar que tu página no cuente con páginas “no response”, páginas rotas que arrojen error 404 y la calidad de las redirecciones.
Con los resultados de esta pestaña podrás comprobar si se encuentran bloqueadas por robots.txt las URLs que quieres. Así como también podrás comprobar que tu página no cuente con páginas “no response”, páginas rotas que arrojen error 404 y la calidad de las redirecciones. 
URI
La sección URI muestra toda la información sobre las URLs de la página web, especialmente acerca de la forma cómo están escritas. Aquí podrás filtrar la información de esta manera: 
- Non ASCII Characters: URLs que tienen caracteres no pertenecientes a la codificación ASCII.
- Underscores: URLs que contienen guion bajo.
- Uppercase: URLs con mayúsculas.
- Duplicate: acá se detectan URLs idénticos.
- Parameters: en esta sección se muestran las URLs que tienen parámetros, tales como bloqueos por robots, noindex, entre otros.
- Over 115 Characters: aquí se muestran los URLs muy largos.

Titles
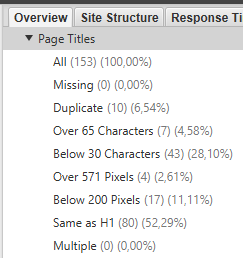
En el panel de Tittles podremos ver información sobre el “tittle” de cada página, aquí podemos ver si existe o no, si están duplicados, si son demasiado largos o cortos y también si estos son múltiples, es decir, si hay varios tittles en una misma URL. 
Meta-description
El panel de Meta-Description se muestra junto al de Tittles, por lo que los filtros y la información que podemos conseguir es exactamente la misma. Podemos ver si la description está vacía, duplicada, si es muy corta o larga y si está multiplicada dentro de una misma página. 
Imágenes
La sección de imágenes es una de las más sencillas, en esta podremos filtrar el resultado para obtener las imágenes que pesan más de 100 kb, imágenes que carecen de atributo ALT o las que tienen este aspecto muy largo. Estos tres aspectos son muy importantes de cuidar cuando buscamos optimizar el SEO. 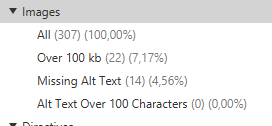
Configuración del Spider
Contenido
Dentro de la opción Configuration – Spider, podemos elegir de qué forma analizamos y procesamos el contenido de la página web:
- Text Only
- Old AJAX Crawling Scheme
- Javascript
 La opción Old AJAX Crawling Scheme es la que viene por defecto, esta emula un sistema de Google que rastrea el contenido AJAX. Este método se encuentra obsoleto desde hace unos cuantos años, sin embargo, sigue siendo uno de los métodos más cercanos al rastreo de la actualidad. Por otra parte, si seleccionas la opción Text Only podrás obtener únicamente el código HTML y la información referente a este. Mientras que la opción JavaScript rastrea el código de este tipo, el cual es sin duda el proceso más pesado de la herramienta, por lo que es normal que tarde un poco más.
La opción Old AJAX Crawling Scheme es la que viene por defecto, esta emula un sistema de Google que rastrea el contenido AJAX. Este método se encuentra obsoleto desde hace unos cuantos años, sin embargo, sigue siendo uno de los métodos más cercanos al rastreo de la actualidad. Por otra parte, si seleccionas la opción Text Only podrás obtener únicamente el código HTML y la información referente a este. Mientras que la opción JavaScript rastrea el código de este tipo, el cual es sin duda el proceso más pesado de la herramienta, por lo que es normal que tarde un poco más.
Robots.txt
La siguiente opción, robots.txt, nos muestra las siguientes tres opciones dentro de la opción Settings:
- Ignore robots.txt
- Show internal URLs blocked by robots.txt
- Show external URLs blocked by robots.tx
 Dependiendo de la opción que seleccionemos podremos ignorar todos los archivos robots.txt de la web, mostrar las URLs bloqueadas por los robots.txt –la opción más recomendada– o mostrar solo las URLs externas que se encuentran bloqueadas.
Dependiendo de la opción que seleccionemos podremos ignorar todos los archivos robots.txt de la web, mostrar las URLs bloqueadas por los robots.txt –la opción más recomendada– o mostrar solo las URLs externas que se encuentran bloqueadas.
Protocolo
Si has realizado una migración de tu página de http a https, te interesa la información que te aportará la pestaña Protocol, que te permite diferenciar entre los dos tipos de direcciones (http y https). 
Sitemap XML
Screaming Frog nos permite crear fácilmente un Sitemap XML, para esto solo debemos hacer clic en la opción Create XML Sitemap y configurar las opciones que queramos: incluir páginas sin index, PDFs, canonical, entre otras.  Podemos dejar cada una de las opciones con su configuración por defecto y seleccionar Next. A continuación, obtendremos el mapa listo por completo, el cual puede ser guardado fácilmente.
Podemos dejar cada una de las opciones con su configuración por defecto y seleccionar Next. A continuación, obtendremos el mapa listo por completo, el cual puede ser guardado fácilmente. 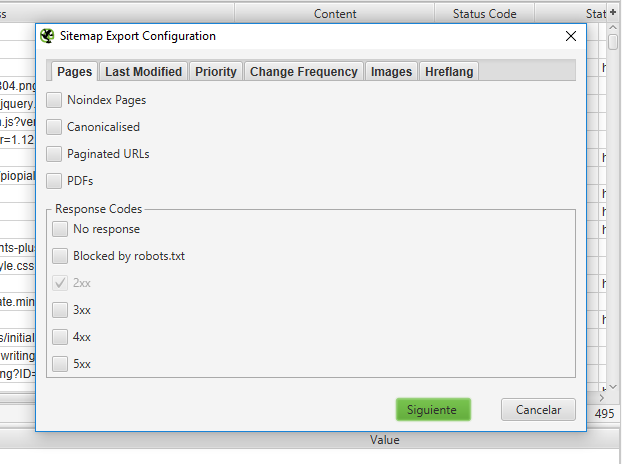
Modo spider, modo list y modo SERP
Si activamos el modo spider la herramienta actuará rastreando la información de URL en URL siguiendo siempre cada uno de los enlaces internos de la página web. Por su parte, en el modo list se rastrearán las URL indicadas en una lista, está deberá hacerse de forma manual. Este modo nos permite analizar de forma práctica las URLs de un sitemap y ver si tienen errores o están dañadas. En esta opción también tenemos que hacer la carga de los URLs de forma manual, pero esta vez en un documento CSV, acá podremos ver cada uno de los tittles y las descripciones. 
Para qué usar Screaming Frog
Las opciones que nos ofrece la herramienta Screaming Frog son muy diversas, ya que no solo podemos aplicarlas a una página web, sino que podemos también analizar la competencia y analizar otros detalles referentes al rendimiento de la web.
Analizar la propia web
Screaming Frog es una aplicación imprescindible para optimizar tu propia página web, ya que podrás conseguir información muy importante que te ayudará a mejorar la calidad de tu página web. Podrás solucionar errores y facilitar la indexación de la información por parte de los diferentes motores web.
Análisis de la competencia
Uno de los grandes beneficios que te ofrece Screaming Frog es que también puedes analizar a tu competencia. Por medio de los resultados sobre las etiquetas, tittles, descripciones y demás podrás ir descubriendo las palabras claves en las que están empleando mayor dedicación.
Gestión de linkbuilding
Screaming Frog nos permite analizar los enlaces externos o salientes, lo cual nos permite analizar los sitios a donde se están enlazando las páginas de la competencia.
Descubrir URLs sin tráfico
Esta herramienta permite ver el flujo orgánico que reciben ciertas URLs en específico, de este modo podrás prestarles mayor atención a estos y optimizar el contenido para mejorar aún más tu página web.
Últimos cambios v. 14.1
- Modo oscuro
- Exportación de documentos a Google Spreadsheet
- Encabezados HTTP
- Almacenamiento de cookies a través del rastreo
- Cantidad de URLs descubiertas por directorio (en vista de árbol)
- Nuevas opciones avanzadas de configuración: ignorar URLs no indexables para filtros en la página e ignorar URLs paginadas para filtros duplicados.
- Filtro atributo alt no encontrado en la pestaña imágenes.
- Pequeñas actualizaciones y mejoras.