
Previous post
Billing +163.76 % than the main project – Put us to the testGood morning everyone. It’s been a long time since I’ve been able to start writing and it’s to the point where I’ve said enough! And we’re going to do it to comment on a conference I had the pleasure of attending on November 17th on Artificial Intelligence applied to SEO, in which it was presented publicly (I already had the pleasure of seeing it privately and being able to chat with its creators months ago) Safecont, the most advanced tool for SEO analysis and quality of content, as they define it.

I would like to comment on all the points that during almost an hour and a half of the presentation (which was far from long) were commented on by their creators:
- César Aparicio
- Carlos Redondo
- Carlos Pérez
Updated February 1, 2018
Thanks to the advances that the tool is making, today we can test the scope and power of Safecont on small websites with a free plan capable of analyzing 500 URLs in 1 analysis for any domain.
Today Cesar Aparicio is in charge of making some videos on Youtube explaining the potential and each of the sections that have this tool.
It is true that in general it is designed for advanced users, but this type of documentation brings it closer to anyone who wants to improve the visibility of their project in search engines.
I have tried to place the important videos that are published in the tool, and I will be updating the post.
Therefore, I provide you with a generic tutorial of the tool:
And another general video, learn how to use Safecont in 15 minutes: https://youtu.be/5-ENrqCaYgA
Try Safecont Free
The first thing to roll up your sleeves… haven’t you tried it? Well, my prayers have been answered and have already opened a free plan Safecont with 1 domain and 500 URLs to play with what we want.
You’ll tell me what you think…
Integration of Safecont with Google Analytics
This option is one of the last ones to be implemented, and one of the questions I asked them the day of their presentation. Finally, it is integrated in the tool.
The beginnings of Safecont
So far all content quality analysis has been done by humans, by all those SEOs or non-SEOs who have analyzed the problems of a website, and thanks to Safecont we will also be able to count on the invaluable help of the machines.
When Safecont started working on the tool, their initial idea was:
“We will make an algorithm in which you give a content (text, images, videos …) and we will get thanks to Artificial Intelligence (Machine Learning) know if it is quality content or not.”
They quickly found that in the academic, even scientific community, this is something like the Holy Grail. It is almost impossible to evaluate if a single document is of high or low quality. It is always necessary to compare, to compare between a group of documents in order to know if one is better than another. For a given subject, you always need to have several sources to be able to decide.
So in the end they ended up working on a completely different approach, they focused on detecting whether or not it has that quality. For that, they needed to go a little bit to the basics of all this.
The arrival of Google Panda
Many of us lived that era live with our projects and we have never been able to determine if it was noticed so much or not so much in the whole world. Since that first Panda date there have been several updates over time, but it has been documented that the initial Panda affected 12% of all searches, not that it affected 12% of all websites, it has affected much more than 12% of all sites. This algorithm or filter, as we want to call it, affected 12% of the search engine queries, where many sites are displayed in each of them.
Many websites were losing traffic from Panda to Panda without knowing what to do… many sites lost more than 90% of their traffic.
When the first Panda was launched it was a real shock for many people who worked on the Internet and had businesses with that kind of content that did not like the algorithm. Imagine a company like Hubpages (one of the flagship examples of Panda’s first step) that had hundreds of workers… many people had to be fired, there was no other solution. Soon they were able to go back a little bit by passing that “thin content” they had in the user files (each user could write their content there and the system would generate a URL for them where only what that user had published would appear) to a subdomain. This is one of the most classic strategies that have been used to get out of content penalties in the search engine. But then the algorithm was refined and these types of sites, if not done much to change, continued to lose organic traffic update to update.

The impact was huge.
Others affected managed to recover some visibility by changing a bit what they were doing and how they worked their URLs or contents.
And now some general culture: What is machine learning?
Safecont to the rescue
And then comes Safecont, to the rescue, trying to help after more than 2 years in which they had not found a possible solution to this problem.
Let’s see how Safecont was born and how it works inside.
Safecont is a Machine Learning system that analyzes the information that is contained in the web pages that are analyzed by a Big Data system. This allows them to grow or shrink the infrastructure they have depending on the amount of work required.
Technologies used by Safecont
To carry out this work, the tool employs a series of Big Data technology that are currently being widely used.
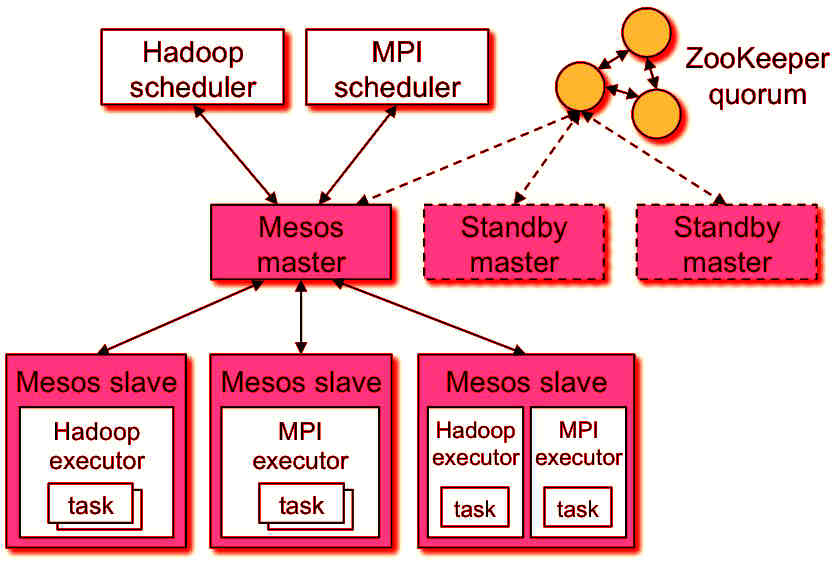
Mesos
The most important software is Mesos, a task scheduler that allows you to manage the various nodes you have in a system and allows you to execute tasks reliably, ie if one of these nodes of all you have fails the system is responsible for relaunching the processes of that node elsewhere automatically, without you having to worry. For this reason the tasks that are executed in Safecont will always end, 100% guaranteed.

So this is an outline of how it can be a normal structure of a system with Mesos, where we have a master node that is responsible for accepting tasks that are requested on the web and is analyzed in the various client nodes that have, which run the software with which Safecont works.
Spark
The main engine for large-scale data processing in Safecont is Spark, an implementation of MapReduce that provides them with various Machine Learning algorithms already implemented in addition to a crawler they have optimized themselves and a non-relational database that stores all the information after processing.

Do you want to know how it is the machine learning process at Safecont?
Clusters in Safecont
Let’s now go to the practical part of the tool, to see what it can really serve us for. So far we have discussed a lot of concepts. The two strangest concepts that you will find in the tool are:
- PandaRisk: the probability of having a domain-wide penalty
- PageRisk: the probability of a URL being penalized
Let’s go with the part of clusters, a mathematical term that in probability could be defined as groups or clusters.
Why Safecont works with clusters? Because they work with a lot of data and must group them. Clusters are made of URLs that have the same pattern. They have introduced the algorithms of Machine Learning, have detected the patterns that may or may not have, which may be considered by Google as positive, negative or punishable and have classified them in the tool. Thus Safecont works to facilitate the work of those who use it.
Safecont is responsible for taking the entire website, get all those parameters that in a normal Excel would be impossible to work, and summarizes it easily in its interface. They distribute the URLs in clusters and tells us things like: there are 1212 URLs with a similarity close to 100%. If as a SEO I want to fix my client’s domain, where do I go? I go directly to the ones I know have a greater similarity, the rest I know will not bring me problems, I do not touch them.
Does the fact that there is a lot of semantic similarity between URLs mean that Google is going to penalize us directly as if it were the only factor it is going to take into account? No. Therefore, even if we have a high similarity in many URLs, we could have a dangerousness in that cluster of URLs not very high. In any case, it would be something that we would have to review more thoroughly.
Video about the Clusters tab
Clusters of Pagerisk
This is quite an interesting feature. It takes all the URLs that have been found in our domain and organizes them in groups by probability of being penalized by Google.
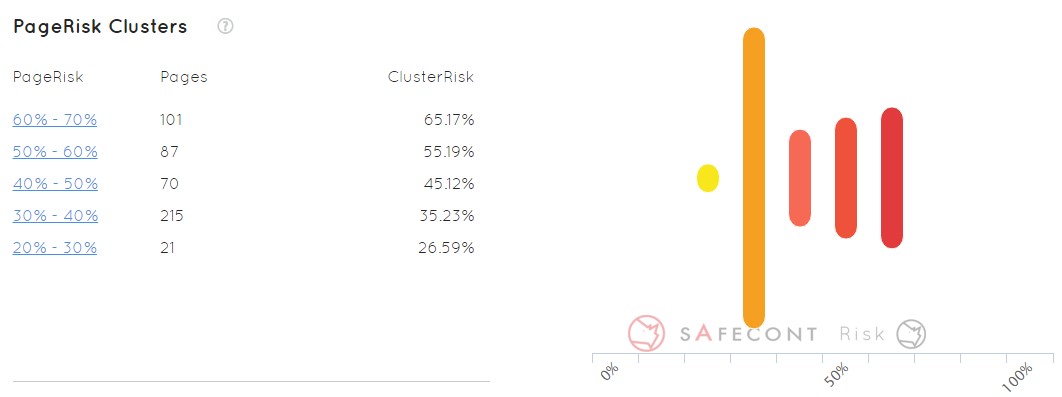
If I analyze a domain I’m not going to have to go URL to URL looking at all the patterns and everything that happens (as long as I’m able to do it), but I go directly to the 101 pages that we see in the previous example that are most likely to be penalized. Then to the next cluster, and so step by step I am correcting my problems.
Video on the Risk tab
¿What can we gain from Safecont?
Detecting similarity
The similarity does not refer to the duplicate content, it is something similar. Duplication is equivalent to detecting exactly the same, literal content, but this is not the case. To give an example: content rewritten by an editor the Safecont system would be able to detect it. This is quite important because on a website, content texts are mixed with headers, footers and other variable things that could make it undetectable if it was simply duplicate content.
We have several ways to study the similarity of content. You can study it by analyzing N-grams, steaming, frequencies of that word in relation to the frequency that word has in the whole domain, distance of levenshtein… there are a lot of patterns.
Let’s imagine that the following image is a domain. 50% of that domain is original content, it has no kind of duplication or similarity with the other pages in that domain, and yet the other half has some kind of similarity, maybe it is a direct copy (the darker the copy of the original part) or it has some kind of similarity index.
 How does it look at Safecont? Like this…
How does it look at Safecont? Like this…

As you can see, the information is ordered by clusters (groupings of URLs). In this case they are grouped by the level of similarity, by the level of danger that each group of URLs has. Here we go from 90 to 100 is a cluster, from 80 to 90 is another … and in the graph on the right the size of the bar gives us easily understand how large is that group of URLs over the total domain. The color indicates the level of danger, from green to red as if it were a traffic light.
When you want to clean up a domain quickly you can see which is more of a priority, in this case the first two clusters of 90-100 and 80-90. At the same time we can see where the most dangerous URLs are concentrated. Above the 50% similarity, the ideal would be to correct it as soon as possible. These are pages that a priori are useless, that already have that content within the domain somewhere else. We are making Google work twice as hard, that instead of one it has to crawl two or N equal pages. We have to understand that a priori everything that is work for Google or complicate things is bad for SEO.
If we click on each cluster, we will have not only the information in more detail, but the list of specific URLs, with the percentage of similarity of each one of them, the possibility of seeing their detailed information, the % of external duplication, the PageRisk, and the capacity to export everything to CSV to be able to work it step by step in an external way.
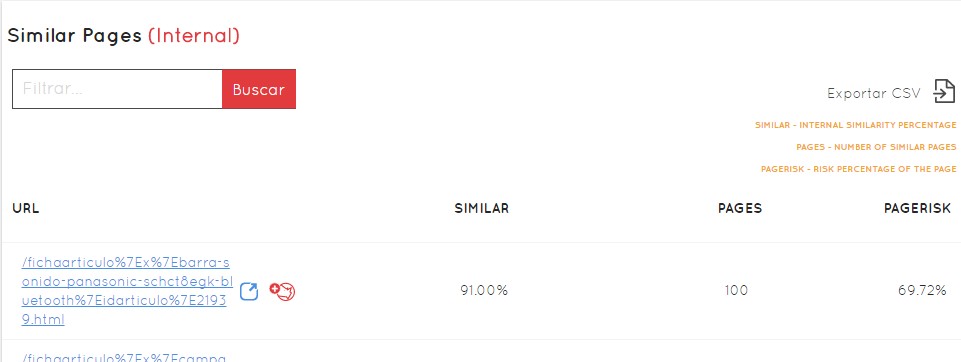
In each URL we will always see two icons, a blue one to go directly to that URL in the browser and a red one to go to the Safecont tab of that particular URL, and see:
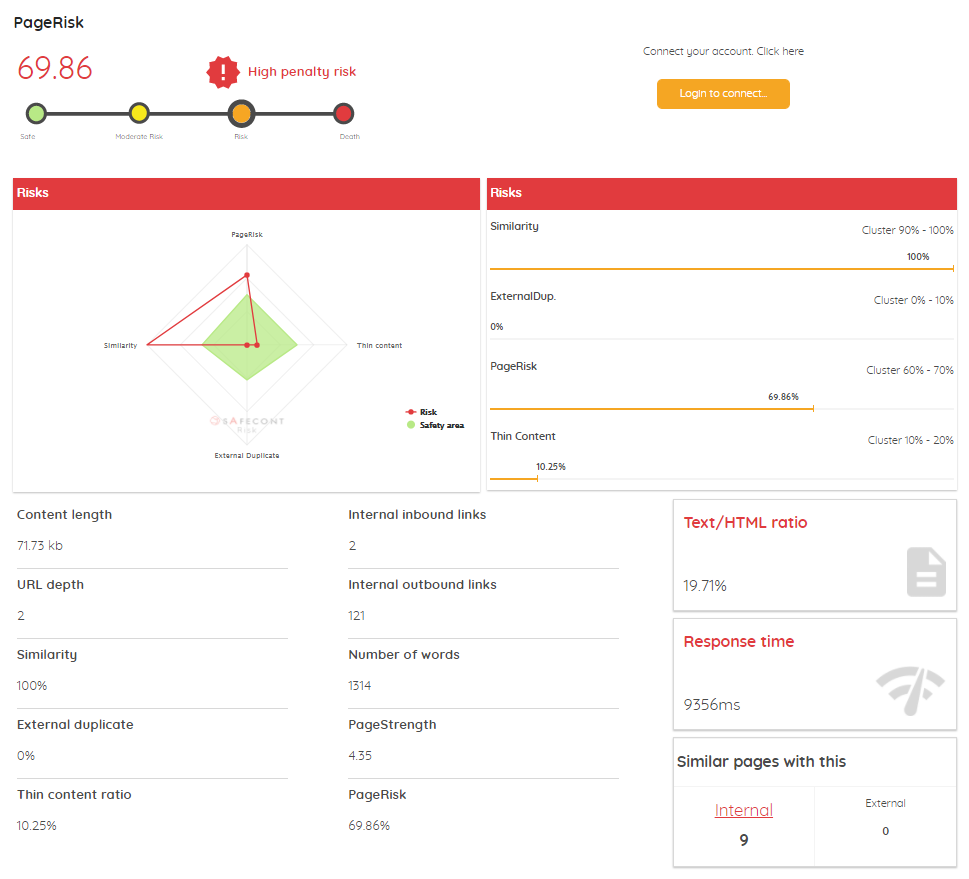
- Danger graph comparing the 4 main factors of the tool: Similarity, PageRisk, Thin content and duplicated external content, with the specific data of each of them in percentage.
- Content size
- Internal links
- External links
- Depth
- Number of words in the content
- Strength of the page (something similar to what would be your PageRank)
- Text / HTML ratio
- Response time
- Number of similar internal and external pages
- TFIDF of the title and an analysis of it
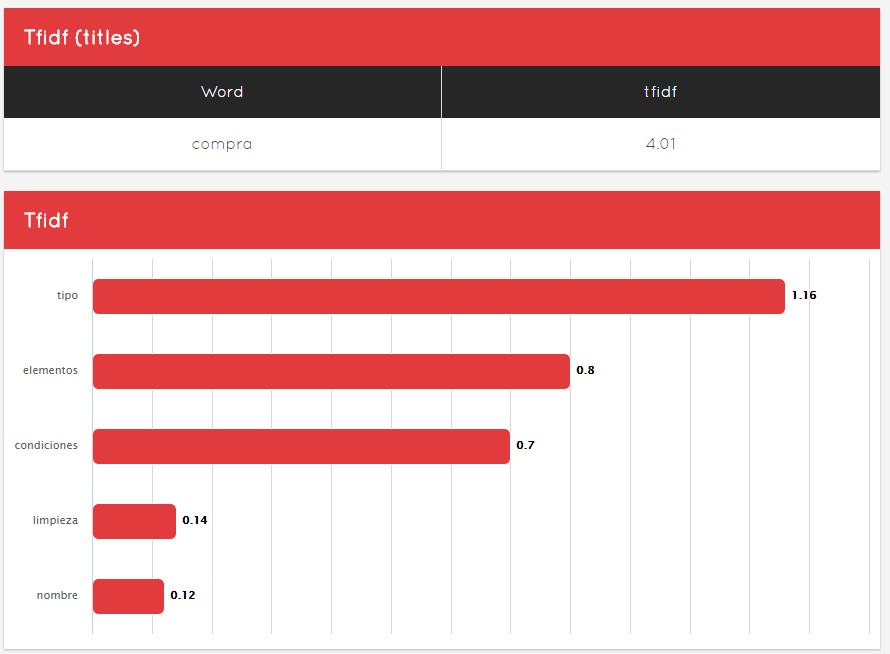
Video on the Similarity tab
Detecting external duplicates
The tool has another tab where we can check external duplicates. These duplicates are the order of the day on the Internet, in short it would be the copy of content from other sources. For example, large universities use this type of technology to detect plagiarism in students’ doctoral theses. Companies, publishing houses, magazines… duplicate content is very common, and it is the main concern of many people who earn their living by generating them.
How do we see this in Safecont? It is similar to the similarity, with its corresponding cluster of URLs.

Below we have, as in the similarity, the URLs listed, and we can see which pages have that duplicate content, either because you have copied them or because they have copied you. In the example above, everything is in green and we don’t have a single URL at risk.
It’s important to know if someone is plagiarizing your content, in case you want to report it or take some kind of action, there are many people interested in this and Safecont offers you every URL that has been copied, the extract and where.
Detecting Thin Content
What is thin content? It is very difficult to define. A priori it is very short content, in short if I have little text on a page directly we could be talking about thin content.
It can be… it is possible… But there are certain pages (for example if you search for “alarm” you will see that the first results are pages with little text content, or if you search for the weather it is very likely that we will simply find results that offer us icons with rain, sun or clouds) that return something specific, solving a need of users without written content … and this is not thin content, it is the content that the user wants to see when he arrives at that page (he wants a system that serves as an alarm or he wants to know what the weather will be like at the weekend in his town).
How to detect if a content is thin content? Safecont summarizes it in 6 points:
- it is trivial
- it is redundant content
- it is scarce content
- it does not solve a need
- it has poor writing quality
- it is out of the question on the web
- it is outdated
In the Safecont interface they follow the same structure as the previous points to facilitate the use of the tool in this section.
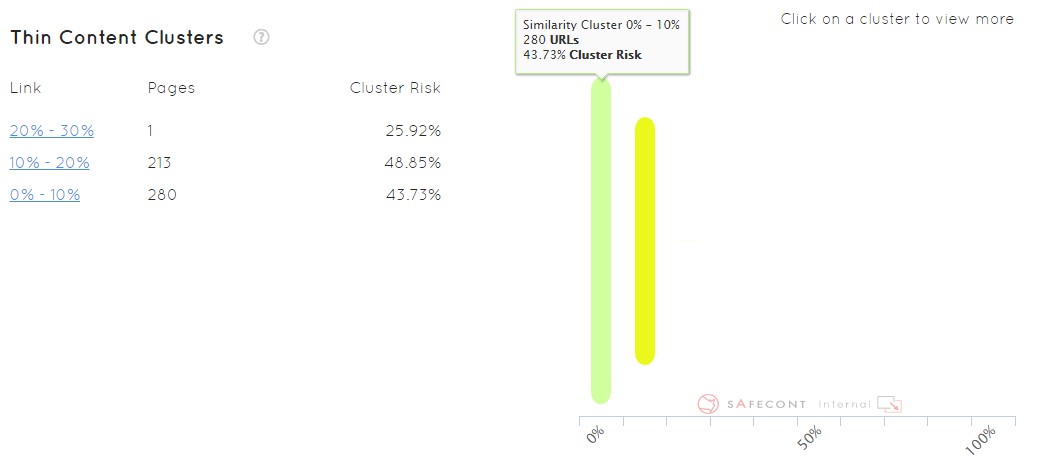
As we can see in the image, we can pass the mouse over any of the bars and observe that information appears for each cluster, with a percentage of similarity, the number of urls and the danger of penalty. As always, we can click and see below all the URLs that compose it to work directly on them.

Semantic analysis
Safecont has introduced a section of semantics where you can know at a glance what are the most relevant words within the website, a contrast of the keyword with all the URLs of the rest of the domain.
We can see in the interface a three-dimensional representation (although Safecont works with 1000 dimensions) to see it easily.

In this three-dimensional box, we can see dots that are equivalent to themes. The more distant they are from each other, the less they have to do. In this way we can see if the themes that a domain works on are related to each other or not.
As we can see, the themes of this site seem not to be very related to each other, all the themes it talks about are quite disparate (except for the blue dots). An excess of semantic similarity could also be detrimental, not in all cases, so we have to analyze it in depth.
We can also quickly find thematic clusters that we have no idea why they are so separated from the rest (as in this example the green one) and analyze if the structure is incorrect and does not correspond to what is usual in my website. I can pass the mouse over it and it will tell me which cluster of URLs it belongs to (in the example to cluster 6), how many URLs it has (88) and which clusterRisk it is (36.07%)
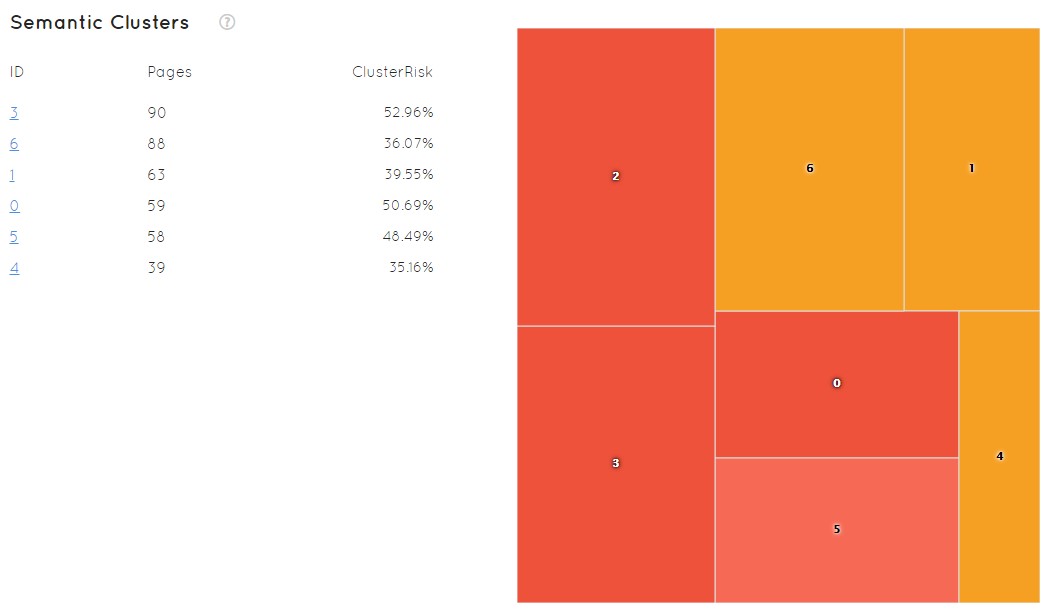
Knowing the cluster number, on the same screen we have another graph that allows us to see it in depth. The ID allows us to recognize it, it shows us the number of pages and the clusterRisk summarized for each one of them.
At the same time, a graph appears that allows us to see quickly the state of my site where the size of the squares and the color given quickly to understand the problems that could have and the situation in which I am. Red implies more danger, orange less… In this example we do not have any green that would be optimal, which means that we do not have semantic groupings that are safe, a priori, to be penalized.
To go deeper I can click on cluster 6 and start working. We will see all the URLs we have in that cluster. We will see the percentage of similarity that it has (how similar are those 88 URLs that were included in that cluster that I could consider dangerous), it is going to tell me the danger that it has of being penalized by Google or not to be penalized and then it will show us all the URLs.
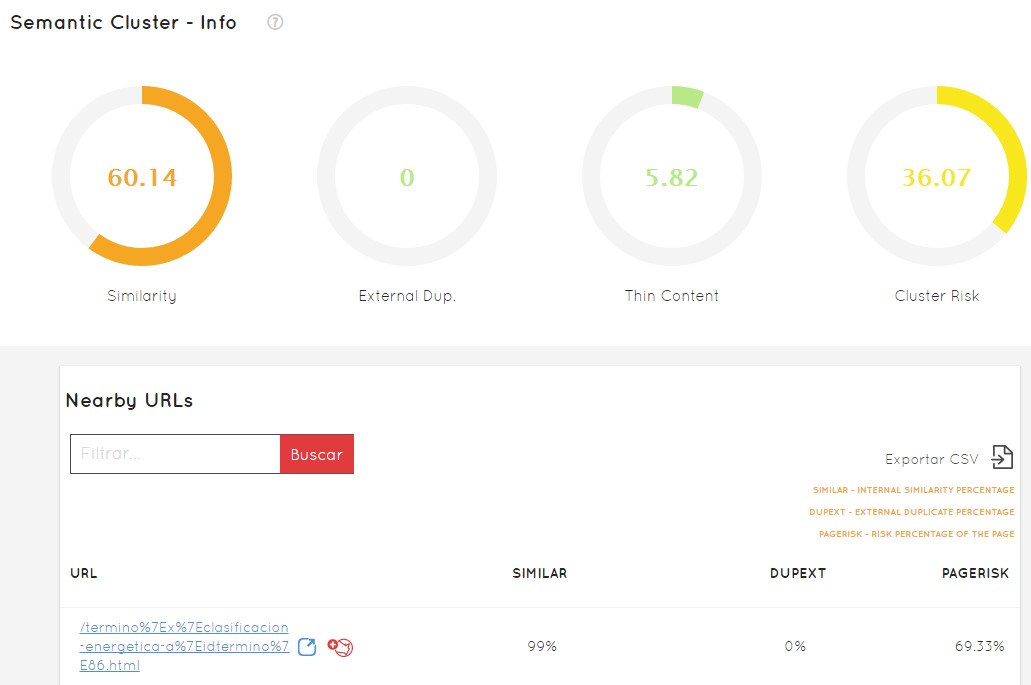
Just by clicking, we will be able to see which patterns are damaging my project. Doing this by hand, without someone showing you like this, could be work of months or luck… and in a competitive world like this we can no longer afford it.
Web architecture
We will be able to take advantage of this section as we will see now.
Let’s talk about large or small sites would be indifferent, obviously the larger the site and more factors we want to analyze, the more complex the issue.
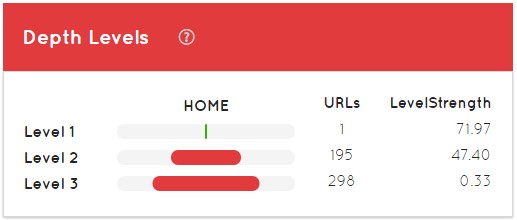
The first thing that appears to us is the level of depth of the website, with the home page as level 1, categories, subcategories, etc. The more time a website usually has, usually the structures are changing, new levels of depth appear, etc.
Calculated PageRank
LevelStregth is what tells us the “PageRank” of each level of depth. As an example, when positioning those 298 URLs that we have at level 3 it will be much more complicated than positioning the other 195 that have a 47.40 LevelStrength.
Generally, the home page should have a LevelStrength of 100, but as it is a partial analysis in the previous image does not appear as such. The correct thing is that the second level should also have another 100. If the second level has less than that, it means that my internal link is badly done, I have problems, the link juice of the home page is not arriving correctly to the next URL of our site, especially when we are talking about level 1 to level 2.
In a supposed level 10 of depth we could have 0,0X, they are quite complicated questions to solve but Safecont is a clear facilitator of the same ones.
As we see in the image above, we return to have colors to quickly intuit what is right or we must correct. We can click and access the information of that level and the list of URLs that form it. Look:
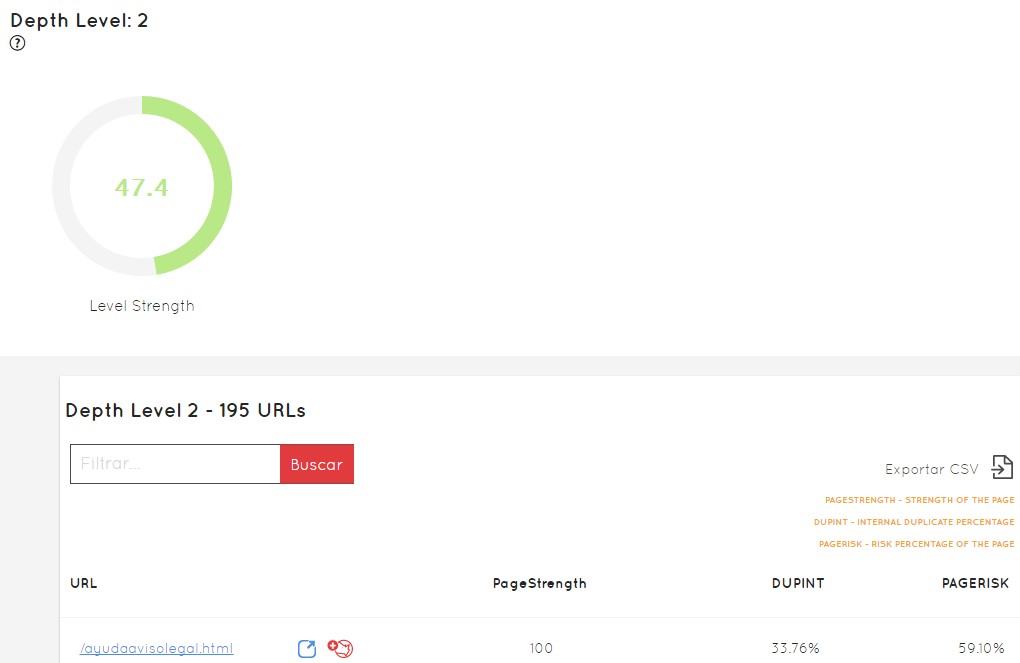
The PageRisk of each URL
What I should try to optimize is the entire link structure within my website.
How are we going to do this? We must analyze URL by URL.
The first thing we see in the example URL is that that URL has an internal duplicate of 33.76%, which means that I already have other URLs with that duplicate content or very similar . I can click on it and see what it has to correct it:
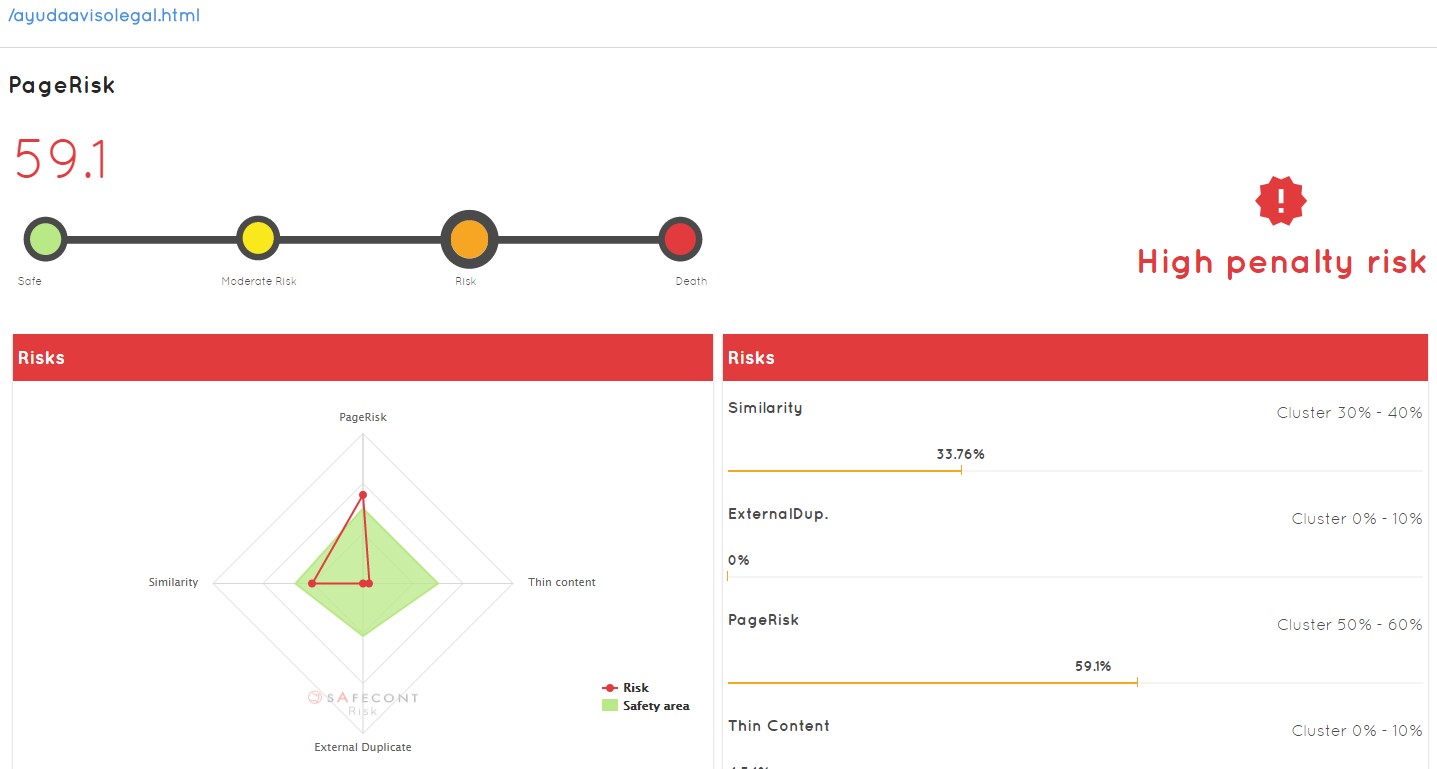
We quickly see that it has a high rate of similarity (but within the safe part) and a high pagerisk, therefore, to be corrected. It may be that not only are you sending links to sites that are not correct, but you may also be sending links to URLs that are duplicate content. At a glance I know which pages I have in lower levels are receiving links from a higher level, links that I am missing and that on top of that are taking me to sites that Google will probably penalize me for later. In addition to those pages in turn have again links to more pages that are duplicated, unoptimized content, etc …
The reliability that the guys at Safecont have achieved is around 82% … something that manually we could not achieve a priori in any of our decisions.
Hubs y Authorities
On the other hand, we can see a graph within the architecture tab with Hubs and Authorities.
Hub: it is a good site where they have to put a link for me to get authority
Authority: it is a site where I would put content because it is very relevant in the eyes of Google
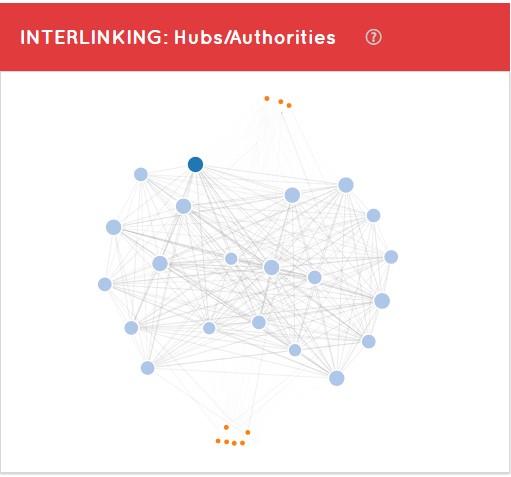
This chart is accompanied by a table of Hubs ordered from highest to lowest by their HubValue
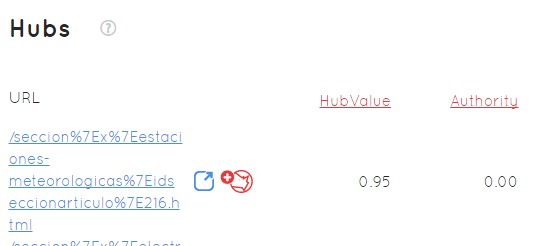
If I want to put a link on a specific URL, the higher the Hub value, the more powerful that link will be. But what the other value in this example is telling me is that that URL is not a good site to publish content because it has little Auhority when positioning.
The Anchors of the internal links
In the last section of the architecture tab we see what happens at Anchor level with the internal follow links on our page.
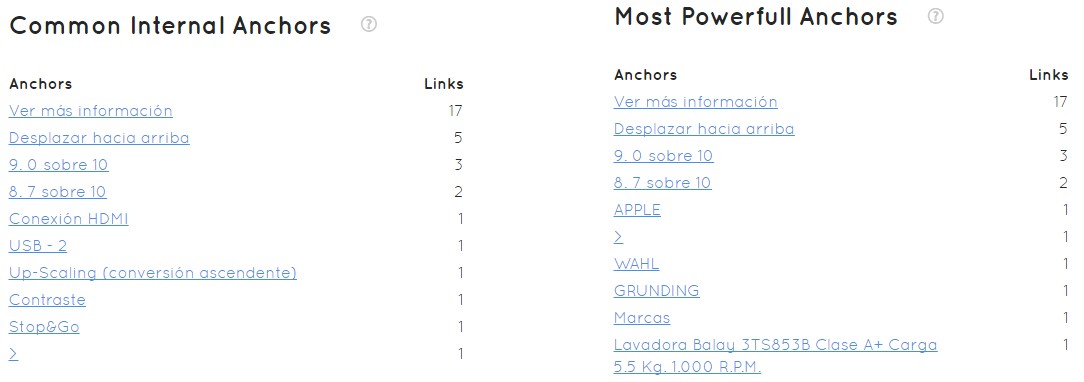
Just as we have to optimize the amount of links we have, we must also try to optimize the appropriate anchor to position certain landing or categories, subcategories within our website.
We see that the most common is “See more information”. This is not logical since it is not our business, but neither is any of the following in a website that is dedicated to the sale of appliances. These keywords are not something we are interested in positioning.
On the other hand, we see that the anchor that gives more relevance to the pages, is also “See more information”, 17 links… it is the most common and on top of that it is not worth it at all. The most common anchor does not have to be the most powerful anchor, since each anchor and each link has a PageRank level, and Safecont calculates it and tells us: this APPLE anchor is in these specific URLs, has 0.259 strength and has been used once.
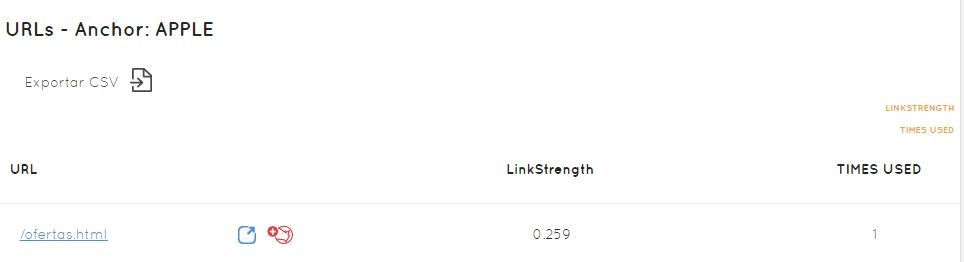
From here I can determine:
- in which Hub I have to put a certain link
- in which Authority I have to put certain content
- I have “See more information” repeated in excess 17 times with a follow link that we are not optimizing as we should the relevance of anchor text
- we have seen that on many occasions we are sending links to sites that are duplicate content and are detrimental to us.
Pages in Safecont
Very easily, a list of all the pages we have will appear, indicating which is the most damaged and possibly penalizing our site, even the one that is better. This does not mean that the last one is good or that the first one is bad, everything will depend on the domain we are working on.
In the interface, this tab offers us the basic determinants that Safecont has decided to show us. Behind this there are a lot of calculations on parameters that have not included to summarize the most striking features.
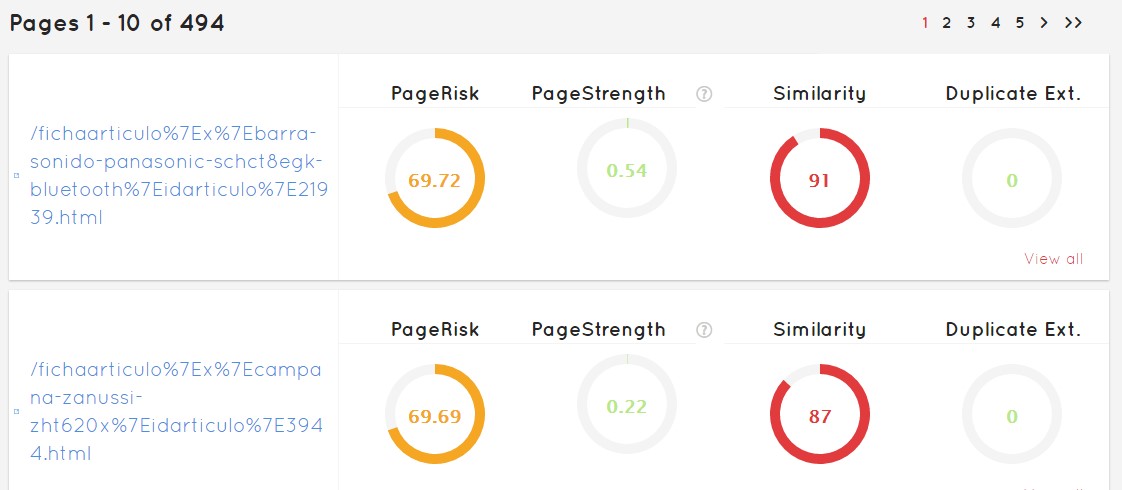
We see that quickly I can go to those who have more problems, and correct in an orderly manner the problems of the website you want to optimize.
CrawlStats of Safecont
Update September 8, 2018
This functionality was released on September 3, 2018.
At a glance, we can see:
- The unique pages of our website
- Non-indexable pages
- Those that do not offer us a status code 200
- Those that exceed the tracking limit
As always in Safecont, we can export them in CSV to work with them. In addition, it offers us an index on the facility of crawling the site to a bot, that they denominate Crawl Health Score.

In a second panel, it offers us a comparison with the previous crawl, to see differences after the work done or by changes in the state of the site.
As a summary, in a third panel, there are 3 boxes showing at a glance:
- The non-indexed URLs (they are not the ones indexed in a search engine, but those that we know perfectly well will not be indexed, such as redirections)
- Those that do not offer a status code 200: errors 4XX and 5XX
- Unique URLs and those canonized
Finally, they offer us a graph that I particularly like, where we can see the URLs crawled by level.

At the same time, from each level, we can see the URLs that do not have code 200, the non-indexable ones, the unique ones and the Score or index that we mentioned before, of that level in particular. Quite actionable, don’t you think?
Safecont Home Page
To conclude this analysis, I would like to talk about the Safecont homepage, which will clearly show us several problems after the analysis:
- Main problems of our domain
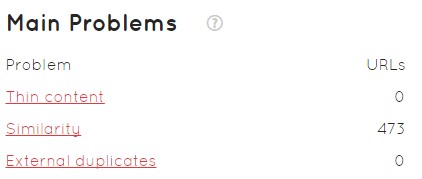
- Probability of being penalized by Panda

Here as we see the number is 61.57. It is not a penalty percentage, it is a number from 0 to 100 possible points. Out of 100 points I could have a domain, how many points do I have? It is not a probability.
- A graph of the situation of the domain by the main factors of the tool and its “area of tranquility”

- Clusters of URLs and specific URLs with a higher index of danger
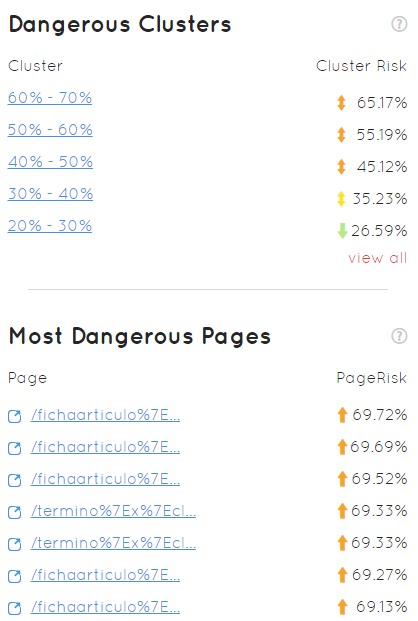

In definition, the idea is to end up with a 35% probability of being penalized by Panda, and not with 65%, which is the usual average of what Safecont usually finds in its analyses.
How to fix a website with Safecont
Once we have analyzed the web with Safecont, we have seen everything that is wrong, the clusters, the URLs, etc… and I know what happens, we must get to work.
How do I fix all the problems with my website?
Poor quality content in some parts of my website can impact the ranking of the entire web, and therefore removing poor quality pages, merging, improving content on individual pages, or moving poor quality pages to a separate domain, can help you get Google to rank and rate your site’s content much better.
Methodology of work with Safecont
In its presentation, Safecont presented this methodology to work with its tool:
- First we separate the garbage, the URLs that Safecont is telling us are not good, that they do not have a good quality grade, that they can be penalized, and we separate them by page type: if they are categories, if they are tabs or if they are queries…
- We study what percentage each of these groups represents in the total of all the bad pages. Example: the domain has 50K and I have 10K bad pages, and within those bad pages the categories are 1K. We see what percentage it represents within that total of bad pages, and we take out the percentage of the total pages of the domain, in the example of the 50K.
- We take out the organic traffic of these types of pages. Example: how much organic traffic arrives at categories, or product files or the home page, etc…
- We compare the risk of penalization of the domain on an imaginary X-axis and on the Y-axis the number of URLs that we have. We would have an imaginary line that would determine the Panda penalty, but if I reduce the number of bad URLs, the risk is reduced.
- We evaluate the changes that will be made. How much traffic will I lose because of the cleanup? For example, if you are going to delete URLs, you are going to redirect, whatever you consider… it will probably mean a small or large loss of traffic.
- Assess how much traffic you have already lost to Panda Update if it is an old domain and has suffered a penalty. If it’s new, you don’t really know how much you’re losing because of the Google quality algorithm. If the traffic you are going to lose is less than the traffic you have already lost or are losing, go ahead and clean it up.
The next thing to do if we are going to continue is to select the different page typologies and decide what to do with them.
Solutions to the problems detected
Possible solutions (each one appropriate to a type of page or problem)
- 301 redirection: if we have several pages that are the same You choose the one you decide you want to position and the rest you redirect to it.
- Meta noindex: for example if some page despite having content that Google may consider of poor quality … may be important for the user, and it is important that it appears in the navigation of your site and the user reaches it.
- With the robots.txt file: You can also put a Disallow at robots.txt level. There are many that we may not be able to define at the page level the robots tag, and we can do it from there, even in mass.
- Canonical Meta: Write down all the URLs that could be dangerous and similar to another one, write down a canonical to tell Google that this is a version that I have for other reasons and I want you to write down this one.
- Unify content: if we have several URLs with thin content, scarce, small on the same topic, take all those small, group it and unify them by building a single page with all that content.
- Enrich: this depends on the volume of URLs we have, sometimes it is feasible and sometimes not. It consists of improving the content of a URL, enriching it with our data, the content that we see that could be useful to the user, etc..
From 40% of PandaRisk, we should start to worry.
In the presentation we had, we were shown the case of Emagister, which has been using the tool for quite some time now. After losing traffic since 2011, they have now managed to increase traffic by 160%, considering that they were in decline.
Conclusions
This tool does not replace your SEO, the person responsible for the visibility part in searches, but is a facilitator. Really when you’re faced with a penalty case or simply a new project, whether it’s bigger or smaller, it’s very difficult to find where the problem is. There are things that you get to see easily but there are others where the volume of data and information is such that you don’t know and you end up in a trial and error process that will take months. Months not to solve it, but to realize what is happening.
With Safecont, in a few hours after entering your domain you will see if you have problems or not, what specific problems you have and where. And from there you can begin to work, to put solutions, and facilitates this task thanks to clustering, monitoring parameters to focus on working alone on what may be the worst part of your website or the worst quality, instead of working with a large volume of URLs without being able to focus.
On the other hand, it is important to emphasize that Safecont is not only Panda’s analysis. It is content analysis, including text anchor and architecture improvement. At Safecont they use Panda because it is a term we all more or less know and handle, but it is the optimization of the site itself in general at the click of a button.
Question Shift
1. First Opinion
Congratulations on the tool, I think we finally have a tool that will be able to give us solutions, not in the short term, but the possibility of prioritizing. In the end, with penalties, after many years of penguins and pandas and managing to learn what they are and how to deal with them, the tool is really good for trying to detect which areas are most affected and prioritize what you would do and where to start.
After testing the beta with a project, the most interesting thing is the possibility of jumping from cluster to cluster and prioritizing over what is most at risk, not only at a general level with PandaRisk, but also with the duplicity, similarity and architecture.
The architecture part I think has some brutal possibilities, because it allows us to improve the internal linking and allows us to detect which pages become wildcards or pages that have a lot of authority. So I think that for big projects it is very good but for medium projects of 20-30K the tool also has quite a lot of power. It’s going to allow us to, say, quick wins so to speak, and go ahead and start climbing in the traffic recovery if we’ve already been penalized or avoid being penalized. So I think it has a lot of potential and the integrations that you can make in the future I think they are going to have a lot more potential.
Finally, maybe in big companies that have a large or internal IT team, they have more possibilities to do things and keep moving forward to get out or improve traffic, but maybe in SMEs or smaller sites, you need that prioritization to go to those URLs that can hurt you the most and improve that part, and maybe the rest you don’t have to invest so many resources in working on many things.
The interface part is quite good, it is very intuitive, PDF reporting for the whole project… I understand that you will improve all this and move it forward. Something bad, maybe not bad as such, but for those who already know SEO in a very advanced way, maybe it is less difficult to understand the metrics and concepts. A support page… would help other profiles land on some concepts that could be complex.
2. Similarity?
Pedro: I have seen that the similarity of content at the internal level is very good, but how do you analyze the external domains?
Safecont: We do this with our own technology similar to Copy Scape (I would say more powerful). We apply it for both the internal and external similarity part. In the end we can know if a content is present in any other URL on the Internet. The whole Internet is almost impossible, but we have a higher volume in the tests we have done than the competition.
Pedro: Do you think the similarity of external content is affecting Google Panda right now?
Safecont: No, it’s not within Panda, this was explained by Google at the time. They had an algorithm that was based on that (I think I remember Scraper update or similar) that simply penalized sites that copied content from each other. Then there is Panda, which is something else, it evaluates quality. What happens is that if you have a site where you copy a lot of content…
Pedro: of course, but more than “copying” I’ve stayed more with the idea that you said of similarity… on a general level it’s something that practically everyone does…
Safecont: everything depends on how you rewrite it… you can read a text, turn around and write your version of it… probably there neither we nor anyone else can detect it, although in part yes. But if what you have done is take the document, change two sentences, change four words, put a couple of synonyms … the tool is capable of detecting it.
3. Integration with Analytics
Alberto Fernández: first of all, congratulations on the tool. It is very good to know the URLs that are wrong, the URLs that… but for example an integration with Google Analytics to compare with organic traffic directly… I think it can be interesting.
Safecont: we are thinking about it
4. Robots virtual
Alberto Fernandez: when you pass a domain and has for example 1K million URLs, I guess you follow the robot to know what to analyze and what not, content types and things like that to know what to analyze and what not . Have you considered an internal virtual robot to say: I want this now, but not the rest, etc… in different analysis?
Safecont: we have it as an idea, that the client at the end can a little filter what parts he wants us to analyze crawleemos and what parts not.
5. Tested domains so far
Alberto Fernández: How many domains have you already passed through the tool? Within this ecosystem of Machine Learning… where are we?
Safecont: most of the domains we have passed are large domains… The number of urls analyzed goes by millions.
Safecont: in the end it is a training process, and we introduced domains to get a point of quality that we believe was appropriate. The current reliability is 82%, that means that our algorithm thinks the same as Google 82 times out of 100. Of the 18 that remain, I do not remember if they were 14 or 15, were because we overpunished more than Google. Nowadays we can be much more restrictive. It’s not a bad thing, but you’re really going to clean up more than you would need to be penalized by Google.
This type of technology that we use is available to anyone and is affordable, but training an algorithm is very expensive, you need many iterations, a lot of data, a lot of information, many days of processing… and that’s the critical part.
6. Pricing plans, unique recursive projects and agencies
Alberto Fernández: this for small domains would not be necessary, with an Excel and such we could perfectly manage, but for medium domains that have 10-20K Urls… you have considered some kind of plan that allows the recursive use of the tool for an agency.
Safecont: for a domain that has 20K URLs the question is that the hours you charge for consulting (50 ? or 100 ? or whatever you charge each) if you have to work 50K URLs and with this you only have to work 5 hours… the rest is margin for you…
Safecont: by the way, we haven’t talked about what it will cost… the web is already online, we have already removed the beta part and you can visit it. It goes by packages, packages that go by number of URLs you can analyze and there is a limit per number of domains. Each package will allow you X domains until you spend the URLs. There is an agency package that will allow you to work with many domains… I don’t know if I understood your question correctly or if it goes that way.
Alberto Fernandez: yes, went by the two parts, one by that part agency of a same dominion, and another by a same dominion to which you attack recursively and to be able to go seeing that improvement.
Safecont: you’re going to have credits, if you run out you’ll be able to buy them (1 credit – 1 URL). If you need to analyse 2000 more URLs, then you buy them at the same price as you paid for the package.
Safecont: One thing we see as being quite good (which we’ve done by trying to be as honest as possible) is that Safecont doesn’t have a monthly fee, we invoice for each crawl and each analysis that you do. So, I do an analysis, you know the picture of the whole domain and you know its problems? why do we do it like this? Because it is very difficult that some arrangements or some solutions that you have to implement like these you do them in a short time… there are people that work for example by quarterly projects, then the average time to implement all this can be of a month, two, three… then why pay a monthly tool when you are going to take three months in doing the changes… it did not seem honest to us. You take a picture, you solve what you have to solve, and then you go to see if that is efficient, if it is going to serve you, if you are still in danger… and you take another picture. Then you pay for every analysis you do. Anyway, we’ll see the feedback from the clients… and if any changes are needed.

In addition, today we have learned that the domains will be active domains, that is, we will be able to consume the 5000 URLs by analyzing 10 domains out of 500. With this, I particularly think that the price is much more affordable for certain types of projects.
7. How to get a beta?
Another assistant: to get the beta? Because this seems very good to me but I now go to the agency and say: there is a tool that… they will want to test it.
Safecont: until now our website was a simple platform to order betas, with your name, email and domain. From now on you can’t, but logically if someone wants to try it then simply contact us and… hey look I have this domain, I would like to test the tool…
Safecont: it will also depend on the domain. When we opened the betas there were people who sent us directly a page in HTML and is already to analyze, and I think it has neither content, nor duplicate or anything … so while they are things that you can take a little more advantage to be a little more visual, no problem. You can write it to us through Twitter or to the email of the web, because betas were coming recurrently…
8. What is the limitation of URLs in the betas?
Another assistant: what are the limitations of the URLs you have entered?
Safecont: it depends on the domain you have sent us. They have been small, from 500 to 2500 URLs in some particular case. Generally we do a weighting but you have to get used to the idea because it can give you a scoring but only on the URLs that you have seen, but at least to see more or less how the system works. You can write to us…
9. Is Safecont only available in Spanish?
Another assistant: do you do the semantic analysis only in Spanish?
Safecont: No, it’s multi-language, it works in all languages because the way to analyze it is completely different from word to word.
Safecont: when we start the development process we evaluate a lot of options, algorithms, work generating dictionaries by language … what happens is that in cost is unfeasible and in the end works much worse. This is math, the language we are in doesn’t matter because it analyzes a large volume of context and takes out certain formulas that are common, so we don’t care if it’s Spanish, French, Italian… we don’t care. We have not tried it in anything else but Spanish, Catalan, French, Italian and English.
Safecont: and in Filipino too. And that’s enough. I was telling you that there was a drawing very similar to the other one…
And now… Any questions about Safecont? Any comments are welcome and if they are doubts and I can answer them, great. If I can’t, I’m sure one of the members of Safecont will let me answer them.
See you next time!