
Post anterior
Gestión de Stock EcommerceLa optimización del archivo robots.txt es un aspecto esencial para el SEO de un sitio web que les dice a los motores de búsqueda qué páginas o partes de un sitio web pueden o no pueden ser rastreadas.
Sigue leyendo para que puedas entender que son, como aplicarlo a tu web, cómo crear uno siguiendo nuestra guía y para qué sirven los robots.txt en tu web de manera práctica.
¿Qué son los robots.txt?
Robots.txt es un archivo de texto que indica a los rastreadores de motores de búsqueda qué páginas de un sitio web pueden acceder. Los rastreadores utilizan este archivo para determinar qué páginas indexar en Google y rastrear.
Ejemplos:
- Para evitar que los rastreadores indexen una página de inicio de sesión:
User-agent: *
Disallow: /login
- Para permitir que los rastreadores indexen todas las páginas de un directorio, excepto una:
User-agent: *
Allow: /directory/*
Disallow: /directory/ejemplo
- Para permitir que los rastreadores rastreen un sitio web con frecuencia:
User-agent: *
Crawl-delay: 1

Funciones de los robots.txt
- Controlar el rastreo de las páginas de un sitio web por parte de los motores de búsqueda. Esto puede ayudar a evitar que los motores de búsqueda sobrecarguen el sitio web.
- Controlar la indexación de las páginas de un sitio web por parte de los motores de búsqueda. Esto puede ayudar a evitar que las páginas que no deseas que se muestren en los resultados de búsqueda sean indexadas.
Combinar rastreo e indexación
Para que los motores de búsqueda puedan indexar una página, primero deben rastrearla. Robots.txt puede utilizarse para controlar el rastreo de las páginas de un sitio web.
Esto puede ayudar a evitar que los motores de búsqueda sobrecarguen el sitio web y que indexen las páginas que no deseas que se muestren en los resultados de búsqueda.
Pautas para el uso de robots.txt
- No impida el rastreo de las páginas que contienen directivas para indexar o servir contenido. Si se deben seguir directivas para indexar o servir contenido, no se debe impedir el rastreo de las URLs que contengan esas directivas.
- Controle el rastreo de las páginas web, los archivos multimedia y los archivos de recursos. Robots.txt puede utilizarse para controlar el rastreo de cualquier tipo de página, incluido páginas web, archivos multimedia y archivos de recursos.
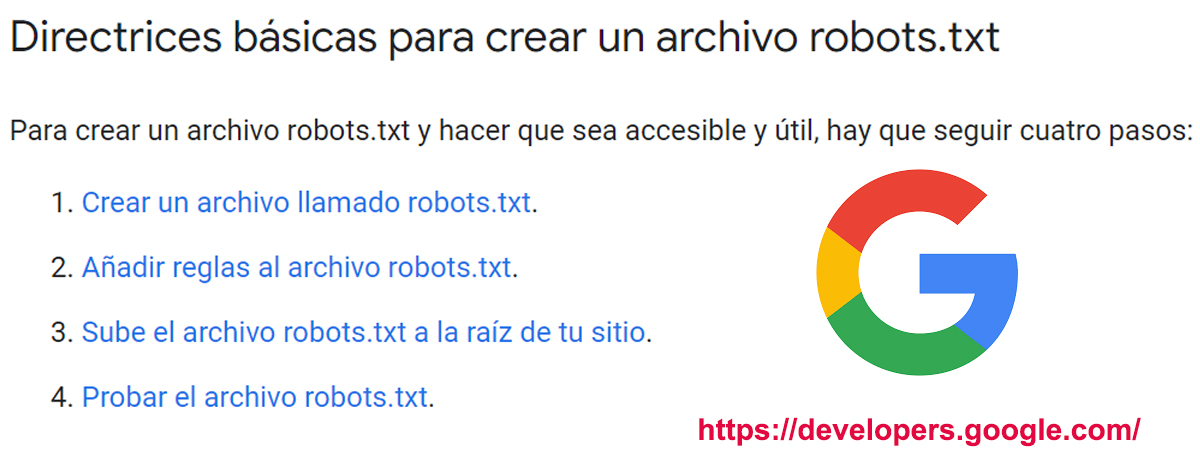
Requisitos y aspectos importantes para crear un robots.txt
- Un fichero por cada subdominio y protocolo: Esto es importante para que los motores de búsqueda puedan entender qué reglas se aplican a cada parte del sitio web.
- Ubicado en la raíz: El robots.txt debe estar en la raíz del sitio web para que los motores de búsqueda puedan encontrarlo.
- Accesible: El robots.txt debe ser accesible con un código de respuesta de 200 OK. Si el código de respuesta es 404, los motores de búsqueda asumirán que no existe ninguna regla.
- Formato UTF-8: El robots.txt debe estar en formato UTF-8 para que los motores de búsqueda puedan entenderlo.
- Límite de tamaño de 500 KB: El robots.txt no debe exceder los 500 KB de tamaño.
Directrices y sintaxis
Sintaxis: La sintaxis de Robots.txt es muy sencilla. Cada instrucción está formada por un campo, dos puntos (:) y un valor. Los espacios son opcionales, aunque se recomiendan para mejorar la legibilidad del archivo.
Los campos de Robots.txt son los siguientes:
- User-agent: Identifica el rastreador al que se aplica la instrucción. Puede ser un rastreador específico, como “Googlebot”, o un comodín, como “*”, que se aplica a todos los rastreadores.
- Allow: Permite el acceso a una URL o un conjunto de URLs.
- Disallow: Prohíbe el acceso a una URL o un conjunto de URLs.
- Sitemap: Indica la ubicación de un mapa del sitio.
Los comodines se pueden utilizar en Robots.txt para especificar un conjunto de URLs. Los comodines más comunes son:
- *: Coincide con cualquier URL.
- ?: Coincide con un solo carácter.
- **: Coincide con cero o más caracteres.
- [ ]: Coincide con un carácter dentro del conjunto.
- [^ ]: Coincide con un carácter que no esté dentro del conjunto.
Ejemplos de cómo utilizar comodines * en Robots.txt:
- Para permitir que todos los rastreadores accedan a todas las páginas:
User-agent: *
Allow: / - Para prohibir que todos los rastreadores accedan a la página de inicio de sesión:
User-agent: *
Disallow: /login - Para permitir que Googlebot acceda a todas las páginas de un directorio, excepto una:
User-agent: Googlebot
Allow: /directory/*
Disallow: /directory/ejemplo - Para permitir que todos los rastreadores accedan a todas las páginas que terminen en “.html”:
User-agent: *
Allow: *.html - Para prohibir que todos los rastreadores accedan a todas las páginas que contengan la palabra “privado” en el nombre:
User-agent: *
Disallow: *[privado]
Ejemplos de cómo utilizar el comodín de dólar ($) en Robots.txt:
Ejemplo 1: Para permitir que Googlebot acceda a todas las páginas que terminen en “.html” o “.css”:
User-agent: Googlebot
Allow: *.html$
Allow: *.css$
Estas instrucciones permitirán que Googlebot rastree las siguientes páginas:
-
/pagina.html
-
/subdirectorio/archivo.html
-
/estilo.css
-
/subdirectorio/otro-archivo.css
Ejemplo 2: Para prohibir que todos los rastreadores accedan a todas las páginas que contengan un número en su nombre:
User-agent: *
Disallow: *[0-9]$
Esta instrucción prohibirá el rastreo de las siguientes páginas:
-
/pagina1
-
/pagina2
-
/pagina10
-
/subdirectorio/archivo1
Ejemplo 3: Para permitir que todos los rastreadores accedan a todas las páginas que comiencen con “/privado” y terminen con “.php”:
User-agent: *
Allow: /privado[0-9]*.php
Esta instrucción permitirá el rastreo de las siguientes páginas:
- /privado1.php
- /privado2.php
- /privado10.php
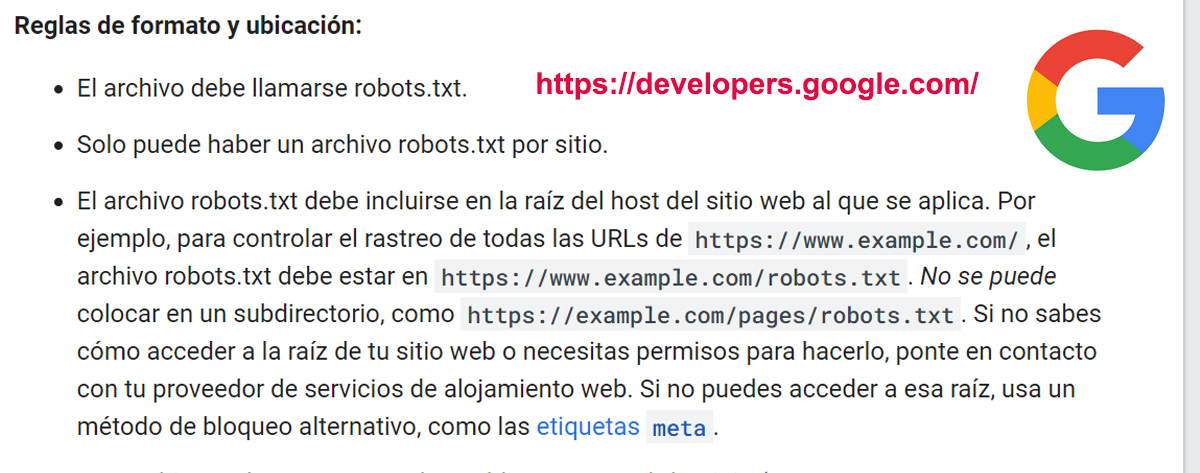
Qué debes saber sobre Robots.txt: Aspectos clave
- Distinción entre mayúsculas y minúsculas:
- El valor de la regla disallow/allow sí distingue entre mayúsculas y minúsculas. Por ejemplo, la regla
Disallow: /paginaprohibirá el rastreo de/paginay/PAGINA, pero no de/paginas. - El valor del campo sitemap sí distingue entre mayúsculas y minúsculas. Por ejemplo, la regla
Sitemap: https://www.example.com/sitemap.xmlsolo indicará la ubicación del mapa del sitiositemap.xml, no deSITEMAP.XML.
- El valor de la regla disallow/allow sí distingue entre mayúsculas y minúsculas. Por ejemplo, la regla
- Prioridad de las reglas:
- En caso de coincidencia de user-agent y reglas, la más específica tiene prioridad. Por ejemplo, la regla
User-agent: Googlebottiene prioridad sobre la reglaUser-agent: *. - En caso de conflicto en las reglas, la menos restrictiva tiene prioridad. Por ejemplo, la regla
Disallow: /paginatiene prioridad sobre la reglaAllow: /pagina.
- En caso de coincidencia de user-agent y reglas, la más específica tiene prioridad. Por ejemplo, la regla
-
Reglas:
Disallow: /paginaprohibirá el rastreo de/paginay/PAGINA, pero no de/paginas.User-agent: Googlebotprohibirá el rastreo de todas las páginas de un sitio web por parte de Googlebot, excepto aquellas que estén permitidas por otras reglas.Allow: /paginapermitirá el rastreo de/pagina, pero no de/PAGINA.
Parámetros
Los parámetros son valores adicionales que se pueden agregar a una URL para especificar información adicional sobre la solicitud. Los parámetros se utilizan para una variedad de propósitos, como controlar el comportamiento de un sitio web, personalizar la experiencia del usuario o recopilar datos.
En general, los parámetros se agregan a una URL después de un signo de interrogación (?). Los parámetros se separan entre sí por un signo de coma (,). El valor de un parámetro se indica entre comillas dobles (“).
Por ejemplo, la siguiente URL tiene un parámetro llamado “name” con un valor de “John Doe”:
https://www.example.com/?name=John+Doe
Los parámetros se pueden utilizar para controlar el comportamiento de un sitio web.
Por ejemplo, el siguiente parámetro se puede utilizar para cambiar el idioma de un sitio web:
https://www.example.com/?lang=es
Los parámetros también se pueden usar para personalizar la experiencia del usuario.
Por ejemplo, el siguiente parámetro se puede utilizar para mostrar diferentes resultados de búsqueda en función de la ubicación del usuario:
https://www.example.com/?location=New+YorkLista de parámetros más usados:
- utm: Pasivo, añade parámetros de UTM a la URL para rastrear el tráfico de marketing.
- page: Activo, permite paginar los resultados de una consulta.
- order: Pasivo, indica si los resultados de la consulta deben estar ordenados o no.
- hl: Activo, especifica el idioma de los resultados de la consulta.
- site: Activo, especifica el sitio web al que se debe dirigir la consulta.
- filter: Activo, permite filtrar los resultados de la consulta por ciertos criterios.
- format: Activo, especifica el formato de los resultados de la consulta.
- callback: Activo, especifica una función que se debe llamar con los resultados de la consulta.

Limitaciones de los robots.txt
El archivo robots.txt es una herramienta útil para controlar el rastreo de un sitio web, pero tiene algunas limitaciones. Estas limitaciones incluyen:
- Directivas no compatibles con otros buscadores: Googlebot y otros rastreadores web de confianza suelen cumplir las directivas de robots.txt, pero es posible que otros rastreadores no lo hagan. Esto significa que es posible que las URLs bloqueadas por robots.txt sigan indexándose en los resultados de búsqueda de otros motores de búsqueda.
- Sintaxis interpretadas diferente, según buscador: La sintaxis de robots.txt es estándar, pero cada motor de búsqueda puede interpretarla de manera diferente. Esto significa que es posible que las directivas de robots.txt no funcionen de la misma manera en todos los motores de búsqueda.
- Indexaciones de URLs por enlaces externos: Incluso si una URL está bloqueada por robots.txt, puede seguir indexándose en los resultados de búsqueda si está vinculada desde otro sitio web. Esto se debe a que los motores de búsqueda pueden seguir los enlaces externos para encontrar contenido nuevo.
Tratamiento de paginaciones en el robots
El tratamiento de paginaciones en el archivo robots.txt es una consideración esencial para el SEO y la indexación efectiva de un sitio web.
Aquí se abordan algunas de las principales consideraciones y prácticas recomendadas en relación con la paginación en el archivo robots.txt:
- Identificación de páginas paginadas en el robots.txt:
El archivo robots.txt debe configurarse para permitir o bloquear el rastreo de páginas paginadas, según sea necesario.
Es importante utilizar las directivas “Allow” o “Disallow” en el archivo robots.txt para indicar si se permite o se bloquea el rastreo de las páginas de paginación.
- Verificación de logs para identificar rastreo ineficiente:
Los registros de rastreo (logs) son valiosos para identificar cualquier problema con la indexación de las páginas.
Se deben revisar los análisis de logs para asegurarse de que los motores de búsqueda están rastreando eficientemente las páginas de paginación y no están encontrando errores de rastreo.
- Necesidad de rastrear paginación:
La decisión de permitir o bloquear el rastreo de la paginación depende de la necesidad de descubrir contenidos profundos en el sitio.
Si el sitio web tiene contenidos relevantes y únicos en las páginas de paginación, es importante permitir su rastreo para su indexación.
- Rastreo sin paginación si existe estructura y enlazado interno óptimo:
Si el sitio web cuenta con una estructura de enlaces internos bien optimizada que permite a los motores de búsqueda llegar a contenidos profundos sin utilizar la paginación, esta podría no ser necesaria.
En este caso, se puede bloquear el rastreo de las páginas de paginación para evitar contenido duplicado.
- Consideración de scroll infinito y carga con ajax o javaScript:
Es importante tener en cuenta si el sitio utiliza técnicas como el scroll infinito o la carga de contenidos con Ajax o JavaScript.
En tales casos, se debe asegurar que los motores de búsqueda puedan rastrear y acceder a las páginas de paginación correctamente.
Tratamiento de los feeds en el robots
Además de la paginación, el archivo robots.txt también puede ser utilizado para permitir o bloquear el acceso a ciertos feeds de contenido, como los feeds RSS o Atom.
La configuración de permisos para los feeds debe hacerse de manera cuidadosa para garantizar que el contenido deseado sea accesible para los motores de búsqueda y otros usuarios autorizados.
La configuración debe basarse en la necesidad de rastrear el contenido de paginación y en la consideración de la estructura y enlazado interno del sitio.
Además, se deben tener en cuenta las técnicas de carga de contenido como el scroll infinito o el uso de Ajax o JavaScript para asegurarse de que los motores de búsqueda puedan acceder a todas las páginas relevantes.
Ejemplos uso de robots.txt para los feeds
Un ejemplo de cómo el archivo robots.txt puede ser utilizado para permitir o bloquear el acceso a ciertos feeds de contenido es el caso de un sitio web que ofrece un feed de noticias.
En este caso, el administrador del sitio web puede querer permitir que los motores de búsqueda rastreen el feed para que las noticias sean indexadas y puedan aparecer en los resultados de búsqueda.
Para ello, el administrador del sitio web puede agregar la siguiente línea al archivo robots.txt:
User-agent: * Disallow: /feed/
Esta línea indica que todos los motores de búsqueda pueden rastrear todas las páginas del sitio web, excepto las páginas del feed de noticias.
En otro caso, un sitio web puede querer bloquear el acceso a un feed de contenido para proteger la privacidad de los usuarios. Por ejemplo, un sitio web que ofrece un feed de comentarios de usuarios puede querer bloquear el acceso al feed para que los motores de búsqueda no puedan indexar los comentarios.
Para ello, se puede agregar la siguiente línea al archivo robots.txt:
User-agent: * Disallow: /feed/comments/
Esta línea indica que todos los motores de búsqueda no pueden rastrear las páginas del feed de comentarios.
Además de permitir o bloquear el acceso a feeds de contenido, el archivo robots.txt también puede ser utilizado para controlar el acceso a otros recursos de un sitio web, como imágenes, archivos PDF o archivos de vídeo. El administrador del sitio web debe tener cuidado al configurar los permisos para los feeds y otros recursos para garantizar que el contenido deseado sea accesible para los motores de búsqueda y otros usuarios autorizados.
Analizando el robots.txt de una web
Analizar el archivo robots.txt de un sitio web es una tarea importante para comprender cómo los motores de búsqueda rastrean y acceden al contenido de ese sitio.
Aquí te proporciono una guía pasos para realizar esta tarea:
- Accede al archivo robots.txt agregando “/robots.txt” al final de la URL principal del sitio.
- Examina el contenido del archivo para ver las directivas “User-agent,” “Disallow,” y “Allow.”
- Comprende que “Disallow” prohíbe el acceso y “Allow” lo permite a ciertas carpetas o directorios.
- Identifica las reglas específicas para motores de búsqueda si las hay, como “User-agent: Googlebot.”
- Verifica si hay comentarios (líneas que comienzan con “#”) para obtener información adicional.
- Evalúa si la configuración es adecuada para tu sitio web.
- Haz ajustes si es necesario, pero ten cuidado de no bloquear contenido importante o permitir acceso no deseado.
Instrucciones para robots.txt en distintos CMS
Ahora vamos a ver cómo podemos crear archivos de robots.txt en los CMS más conocidos para que puedas hacerlo.
Instrucciones para WordPress
- Accede al panel de administración de WordPress.
- Ve a “Apariencia” y selecciona “Editor de temas.”
- Encuentra el archivo “robots.txt” y edítalo para agregar tus directivas.
- Guarda los cambios y verifica la configuración.
Otra forma es creándolo manualmente y subiéndolo directamente desde tu cPanel y otro método usando un plug-in como el de Yoast SEO. La configuración de un archivo robots,txt forma parte de las estrategias SEO para wordPress que puedes implementar en tu web.
Instrucciones para Prestashop
Para crear un archivo robots.txt en PrestaShop, sigue estos pasos:
En PrestaShop 1.6:
- Inicia sesión en el panel de administración de tu tienda PrestaShop.
- Haz clic en Preferencias > SEO + URLs.
- En la parte inferior de la página, haz clic en Generar archivo robots.txt.
En PrestaShop 1.7:
- Inicia sesión en el panel de administración de tu tienda PrestaShop.
- Haz clic en Configurar > Parámetros de la tienda > Tráfico y web > SEO y URLs.
- En la parte inferior de la página, haz clic en Generar archivo robots.txt.
Cómo verificar si el archivo robots.txt se ha creado correctamente
Para verificar si el archivo robots.txt se ha creado correctamente, abre tu navegador y escribe el siguiente URL:
https://tudominio.com/robots.txt
Si el archivo se ha creado correctamente, verás un mensaje de error 403. Si ves un mensaje de error 404, debes crear el archivo robots.txt nuevamente.
Cómo enlazar el archivo robots.txt con el sitemap de PrestaShop
Para enlazar el archivo robots.txt con el sitemap de PrestaShop, abre el archivo robots.txt y agrega la siguiente línea al final:
Sitemap: https://tudominio.com/sitemap.xml
Esta línea indicará a los rastreadores de los motores de búsqueda que deben seguir el sitemap de tu sitio web.
Instrucciones para Shopify
El archivo robots.txt predeterminado de Shopify funciona para la mayoría de las tiendas, pero puedes editar el archivo para controlar cómo los rastreadores de los motores de búsqueda acceden a tu sitio web.
Pasos:
- Inicia sesión en el panel de control de Shopify.
- Haz clic en Configuración > Aplicaciones y canales de ventas.
- Desde la página Aplicaciones y canales de ventas, haz clic en Online store.
- Entra en Abrir canal de ventas.
- Haz clic en Temas.
- Clic en el botón y a continuación, haz clic en Editar código.
- Haz clic en Agregar una nueva plantilla y luego selecciona robots.
- Da clic en Create template (Crear plantilla).
- Realiza los cambios deseados en la plantilla predeterminada.
- Guarda los cambios en el archivo robots.txt.liquid en tu tema publicado.
Recomendaciones:
- Si no estás seguro de cómo editar el archivo robots.txt, puedes contratar a un profesional SEO para que lo haga por ti.
- Es importante revisar tu archivo robots.txt con regularidad para asegurarte de que esté actualizado.
Advertencia:
- El uso incorrecto del archivo robots.txt puede causar la pérdida de todo el tráfico.

Instrucciones para Squarespace
Squarespace crea un archivo robots.txt predeterminado para todos los sitios web. Este archivo permite a los motores de búsqueda rastrear e indexar la mayoría de las páginas de tu sitio web.
Sin embargo, es posible que desees crear un archivo robots.txt personalizado para controlar cómo los motores de búsqueda acceden a tu sitio web.
Pasos:
- Inicia sesión en el panel de control de Squarespace.
- Haz clic en Ajustes > SEO.
- En la sección Archivo robots.txt, haz clic en Editar.
- En el editor de texto, agrega las reglas que deseas que aparezcan en tu archivo robots.txt.
- Cuando hayas terminado, haz clic en Guardar.
![]()
Instrucciones para Webflow
Webflow proporciona un archivo robots.txt que puedes administrar en la configuración de tu proyecto. Aquí su página oficial.
Pasos:
-
- Ve a Configuración del sitio > SEO > Indexación.
- En la sección Archivo robots.txt, haz clic en Editar.
- En el editor de texto, agrega las reglas de robots.txt que desees.
- Cuando hayas terminado, haz clic en Guardar cambios.

Instrucciones para Wix
Para editar el archivo robots.txt de tu sitio Wix, sigue estos pasos:
- Ve al panel de control de SEO.
- Haz clic en Ir al Editor de robots.txt.
- Verá el archivo robots.txt actual.
- Haz los cambios que desees.
- Haz clic en Guardar cambios.
Recomendaciones:
- Antes de editar tu archivo robots.txt, te recomendamos que consultes las pautas y limitaciones de Google para archivos robots.txt.
Para restablecer tu archivo robots.txt:
- Ve al panel de control de SEO.
- Selecciona Ir al Editor de robots.txt en Herramientas y ajustes.
- Haz clic en Ver archivo.
- Haz clic en Restablecer ajustes predeterminados.

Instrucciones para Magento
- Accede al panel de administración de Magento.
- Navega a “Configuración” y elige “Configuración de tienda.”
- Abre la sección “Configuración de robots” y personaliza las directivas.
- Guarda la configuración y comprueba el archivo “robots.txt.”
Otra opción es crearlo manualmente, validarlo y luego subirlo en la carpeta raíz de tu web.
![]()
Validación del robots.txt virtual
La validación del robots.txt virtual es un proceso que se utiliza para verificar que el archivo robots.txt de un sitio web está configurado correctamente para permitir que los motores de búsqueda accedan al contenido que desea que se indexe.
Hay varias herramientas que se pueden utilizar para validar el robots.txt virtual, incluyendo:
- Google Search Console
- Screaming Frog
- RobotstxtChecker
- Merkle
Guía para hacer un robots.txt
Un archivo robots.txt es un archivo de texto que los propietarios de sitios web utilizan para indicar a los motores de búsqueda qué páginas de su sitio no deben indexar. El archivo robots.txt se encuentra en la raíz del sitio web y se utiliza para controlar el rastreo de los motores de búsqueda.
Paso 1: Crea un archivo robots.txt
Abre un editor de texto como Wordpad y crea un nuevo archivo. Guarda el archivo como “robots.txt” en la raíz de tu sitio web.
Paso 2: Agrega las directivas de robots.txt
Las directivas de robots.txt se utilizan para indicar a los motores de búsqueda qué páginas deben o no deben rastrear. Las directivas de robots.txt más comunes son:
- User-agent: Esta directiva especifica el motor de búsqueda al que se aplica la directiva.
- Disallow: Esta directiva bloquea el acceso de un motor de búsqueda a una página o directorio.
- Allow: Esta directiva permite el acceso de un motor de búsqueda a una página o directorio.
Ejemplo de robots.txt
El siguiente es un ejemplo de un archivo robots.txt que bloquea el acceso de los motores de búsqueda a todas las páginas que comienzan con “/admin/”:
User-agent: *
Disallow: /admin/
Paso 3: Revisa tu archivo robots.txt
Una vez que hayas agregado las directivas de robots.txt, revisa tu archivo para asegurarte de que esté configurado correctamente. Puedes validar tu archivo robots.txt utilizando una herramienta de validación de robots.txt, como Google Search Console o Screaming Frog.
Ejemplo de un robots.txt para una web
Veamos un ejemplo de un robots.txt para una web compleja, con un blog, una tienda online y una sección de administración.
Ejemplo de un archivo robots.txt para un sitio web complejo:
# Indica no rastrear o indexar la carpeta "/admin/"
User-agent: *
Disallow: /admin/
# Permite el acceso al blog
User-agent: *
Allow: /blog/
# Permite el acceso a la tienda online
User-agent: *
Allow: /shop/
# Permite el acceso a las imágenes del blog
User-agent: *
Allow: /blog/images/
# Permite el acceso a las miniaturas de los productos de la tienda online
User-agent: *
Allow: /shop/products/thumbnails/
Resumen: Este archivo robots.txt bloquea el acceso a la sección de administración a todos los motores de búsqueda. Permite el acceso al blog y a la tienda online a todos los motores de búsqueda. Permite el acceso a las imágenes del blog y a las miniaturas de los productos de la tienda online a todos los motores de búsqueda.
Consejos para crear un robots.txt
- Escriba un archivo robots.txt claro y conciso. Los motores de búsqueda solo leerán el primer archivo robots.txt que encuentren en un sitio web.
- Use las directivas de robots.txt de manera apropiada. No abuse de las directivas de robots.txt para bloquear el acceso de los motores de búsqueda ha contenido que debería estar indexado.
- Revise su archivo robots.txt con frecuencia. A medida que su sitio web cambie, deberá revisar su archivo robots.txt para asegurarse de que aún esté configurado correctamente.
Al usar un archivo robots.txt, puede controlar el rastreo de los motores de búsqueda y asegurarse de que su contenido esté indexado correctamente.
User agent
La directiva User-agent en un archivo robots.txt especifica el motor de búsqueda al que se aplica la directiva. La directiva User-agent puede ser una lista de motores de búsqueda separados por comas o un asterisco (*), que representa a todos los motores de búsqueda.
Por ejemplo, la siguiente directiva User-agent bloquea el acceso de Googlebot a todas las páginas que comienzan con “/admin/”:
User-agent: Googlebot
Disallow: /admin/
La siguiente directiva User-agent permite el acceso de todos los motores de búsqueda a todas las páginas del sitio web:
User-agent: *
Allow: /Lista de User-Agents comunes
- Googlebot de Google.
- Bingbot de Bing.
- Yandexbot de Yandex.
- Baiduspider de Baidu.
- DuckDuckBot de DuckDuckGo.
- Yahoo! Slurp de Yahoo!.
- AhrefsBot de Ahrefs.
- SEMrushBot de SEMrush.
- Mozscapeo de Mozscape.
- Majestic-SEO de Majestic-SEO.
Otros User-Agents Robots y que rastrean
- Googlebot-Image: Imágenes de Google.
- Googlebot-Video: Videos de Google.
- Googlebot-News: Noticias de Google.
- Googlebot-Mobile: Móvil de Google.
- Bingbot-Image: Imágenes de Bing.
- YandexBot-Image: Imágenes de Yandex.
- Baiduspider-Image: Imágenes de Baidu.
- DuckDuckBot-Image: Imágenes de DuckDuckGo.
Cómo encontrar tú robots.txt
Para encontrar tu archivo robots.txt, sigue estos pasos:
- Abre un navegador web y escribe la URL de tu sitio web.
- Agrega “/robots.txt” al final de la URL.
- Presiona enter.
Si tu sitio web tiene un archivo robots.txt, se abrirá en tu navegador. Si no, verás un mensaje de error.
También puedes encontrar tu archivo robots.txt utilizando una herramienta de SEO, como Google Search Console o Screaming Frog.
Google Search Console
Para encontrar tu archivo robots.txt en Google Search Console, sigue estos pasos:
- Inicia sesión en Google Search Console con la cuenta que administra tu sitio web.
- Haz clic en el menú Herramientas y selecciona Herramientas para Webmasters.
- En la sección Robots.txt, haz clic en el botón Ver archivo robots.txt.
Screaming Frog
Para encontrar tu archivo robots.txt en Screaming Frog, sigue estos pasos:
- Inicie Screaming Frog y abra el sitio web que desea analizar.
- Haga clic en la pestaña Sitemaps.
- En el campo Sitemap URL, escriba la URL de tu sitio web.
- Haga clic en el botón Start.
Screaming Frog analizará el sitio web y mostrará el archivo robots.txt en la pestaña Robots.txt.
También puedes usar extensiones como la SEO meta 1 clic
Crear robots-txt manualmente
Cómo crear un archivo robots.txt manualmente
Pasos:
- Crea un archivo de texto vacío.
Puedes crear un archivo de texto vacío usando cualquier editor de texto, como Notepad, TextEdit o Sublime Text.
- Guarda el archivo como “robots.txt”.
Guarda el archivo en la raíz de tu sitio web. La raíz de tu sitio web es la carpeta que contiene todos los archivos y carpetas de tu sitio web.
- Abre el archivo robots.txt en un editor de texto.
Una vez que hayas guardado el archivo, ábrelo en un editor de texto para agregar las directivas que desees.
- Agrega las directivas que desees.
Las directivas de robots.txt les indican a los motores de búsqueda qué páginas de tu sitio web deben rastrear e indexar. Puedes encontrar una lista de las directivas de robots.txt en el sitio web de Google.
- Guarda el archivo robots.txt.
Una vez que hayas agregado las directivas que desees, guarda el archivo robots.txt. y súbelo a tu web.
Dónde subir el archivo: El archivo robots.txt debe subirse a la raíz de tu sitio web. La raíz de tu sitio web es la carpeta que contiene todos los archivos y carpetas de tu sitio web.
Herramientas que puedes usar
Hay varias herramientas que puedes usar para crear un archivo robots.txt. Aquí hay algunas opciones:
- Generators: Hay varios generadores de robots.txt en línea que puedes usar para crear un archivo robots.txt personalizado.
- Plugins: Si tienes un CMS, como WordPress o Drupal, puedes usar un plugin de robots.txt para crear y administrar tu archivo robots.txt.
Configuración del robots.txt
La configuración del archivo robots.txt es una forma importante de controlar cómo los motores de búsqueda rastrean e indexan tu sitio web.
Además, al agregar las directivas adecuadas a tu archivo robots.txt, puedes evitar que los motores de búsqueda rastreen páginas que no deseas que indexen, o puedes indicarles que rastreen páginas que de otro modo no lo harían.
Aquí hay algunos consejos para configurar tu archivo robots.txt de forma práctica:
- Empieza con un archivo robots.txt vacío. Esto te ayudará a evitar que los motores de búsqueda rastreen accidentalmente páginas que no deseas que indexen.
- Agrega directivas de disallow para las páginas que no deseas que se rastreen. Por ejemplo, si tienes una página de inicio de sesión o una página de pago que no deseas que se indexe, puedes agregar la siguiente directiva a tu archivo robots.txt:
Disallow: /login
Disallow: /checkout
- Agrega directivas de allow para las páginas que deseas que se rastreen. Por ejemplo, si tienes un blog que deseas que se indexe, puedes agregar la siguiente directiva a tu archivo robots.txt:
Allow: /blog/*
- Consulta con un experto en SEO si no estás seguro de qué directivas usar. Un experto en SEO puede ayudarte a crear un archivo robots.txt personalizado que se adapte a las necesidades específicas de tu sitio web.
Ejemplos de configuración de robots.txt
Aquí hay algunos ejemplos de cómo configurar tu archivo robots.txt:
- Para bloquear el rastreo de todas las páginas que terminan en “.php”:
Disallow: *.php
- Para permitir el rastreo de todas las páginas que comienzan con “/blog/”:
Allow: /blog/*
- Para indicar a los motores de búsqueda que rastreen tu archivo, sitemap.xml:
Sitemap: https://tudominio.com/sitemap.xmlhttps://user-agents.net/
Buenas prácticas para el robots.txt
- Empieza con un archivo robots.txt vacío. Esto te ayudará a evitar que los motores de búsqueda rastreen accidentalmente páginas que no deseas que indexen.
- Agrega directivas de disallow para las páginas que no deseas que se rastreen. Por ejemplo, si tienes una página de inicio de sesión o una página de pago que no deseas que se indexe, puedes agregar la siguiente directiva a tu archivo robots.txt:
Disallow: /login
Disallow: /checkout
- Agrega directivas de allow para las páginas que deseas que se rastreen. Por ejemplo, si tienes un blog que deseas que se indexe, puedes agregar la siguiente directiva a tu archivo robots.txt:
Allow: /blog/*
- Consulta con un experto en SEO si no estás seguro de qué directivas usar. Un experto en SEO puede ayudarte a crear un archivo robots.txt personalizado que se adapte a las necesidades específicas de tu sitio web.
Además de estas prácticas generales, aquí hay algunas sugerencias específicas para optimizar tu archivo robots.txt para los motores de búsqueda:
- Bloquea las páginas que no sean públicas. Esto incluye páginas de prueba, páginas de resultados de búsqueda interna, páginas duplicadas y páginas de inicio de sesión.
- Oculta los recursos que no deseas que aparezcan en los resultados de búsqueda. Esto incluye archivos PDF, vídeos e imágenes.
- Utiliza la directiva Sitemap para indicar a los motores de búsqueda dónde encontrar tu mapa de sitio XML. Los mapas de sitio son una excelente manera de decirles a los motores de búsqueda qué páginas de tu sitio deseas que indexen.
- Utilizar comodines para simplificar las instrucciones
Por ejemplo, el siguiente código bloquea todas las URL de categorías de productos parametrizadas:
Agente de usuario: *
No permitir: /productos/*?
- Utilizar cada agente de usuario solo una vez
El siguiente código muestra cómo utilizar cada agente de usuario solo una vez:
Agente de usuario: Googlebot
No permitir: /a/
Agente de usuario: Bingbot
No permitir: /b/
Este código es más fácil de entender y es menos probable que cause errores.
- Utilizar la especificidad para evitar errores involuntarios
Este código muestra cómo utilizar la especificidad para evitar errores involuntarios:
Agente de usuario: *
No permitir: /de/
Este código solo bloquea la subcarpeta /de/ y no las páginas o archivos que comienzan con /de.
- Utilizar comentarios para explicar su archivo robots.txt a los humanos
Aquí con este código se muestra cómo utilizar comentarios:
# Esto le indica a Bing que no rastree nuestro sitio.
Agente de usuario: Bingbot
No permitir: /
Los comentarios ayudan a explicar el propósito de cada directiva y pueden ser útiles para los desarrolladores y para el futuro yo del propietario del sitio web.
- Utilizar un archivo robots.txt independiente para cada subdominio
Con el siguiente código puedes utilizar un archivo robots.txt independiente para cada subdominio:
# Archivo robots.txt para el dominio principal
Agente de usuario: *
Disallow: /privado/
# Archivo robots.txt para el blog
Agente de usuario: *
Disallow: /borrador/- Mantén tu archivo robots.txt simple. No es necesario agregar demasiadas directivas.
- Revisa tu archivo robots.txt con regularidad. A medida que tu sitio web crezca o cambie, es posible que debas actualizar tu archivo robots.txt.
Preguntas frecuentes
¿Cuál es el tamaño máximo de un archivo robots.txt?
El tamaño máximo de un archivo robots.txt es 500 kilobytes.
¿Dónde está robots.txt en WordPress?
En WordPress, el archivo robots.txt se encuentra en la raíz del sitio web. Para acceder a él, puede abrir el sitio web en un navegador y escribir /robots.txt en la barra de direcciones. También puede acceder al archivo robots.txt a través del administrador de WordPress. Para ello, vaya a Ajustes > Enlaces permanentes y haga clic en la pestaña Robots.txt.
¿Cómo edito robots.txt en WordPress?
Para editar robots.txt en WordPress, puede utilizar el editor de texto de su elección. Simplemente, abra el archivo robots.txt en el editor y realice los cambios necesarios. Una vez que haya realizado los cambios, guarde el archivo y cargue los cambios en su sitio web.
¿Qué sucede si no permito el acceso ha contenido no indexado en robots.txt?
Si no permite el acceso ha contenido no indexado en robots.txt, los motores de búsqueda no podrán acceder a ese contenido. Esto significa que el contenido no aparecerá en los resultados de búsqueda.
Sin embargo, es importante tener en cuenta que incluso si permite el acceso a contenido no indexado, los motores de búsqueda aún pueden indexarlo si lo consideran relevante. Por lo tanto, es importante que revise su archivo robots.txt con regularidad para asegurarse de que está configurando las directivas correctas.
¡Espero que esto ayude!