
Post anterior
Meta Title HTML y la etiqueta TITLE para SEOMuy buenas a todos. Hace muchísimo tiempo que no consigo ponerme a escribir y ha llegado un punto en el que he dicho ¡basta! y vamos a hacerlo para comentar una conferencia a la que tuve el placer de asistir el día 17 de noviembre sobre Inteligencia Artificial aplicada al SEO, en la que se presentó públicamente (yo ya tuve el gusto de conocerla en privado y poder charlar con sus creadores hace meses) Safecont, la herramienta más avanzada de análisis SEO y calidad de contenido, tal y como ellos la definen.

Me gustaría comentar todos los puntos que a lo largo de casi hora y media de presentación (que ni mucho menos se hicieron largas) comentaron sus creadores:
- César Aparicio
- Carlos Redondo
- Carlos Pérez
Actualización 1 de febrero de 2018
Gracias a los avances que va teniendo la herramienta, a día de hoy podemos probar el alcance y la potencia de Safecont en webs pequeñas con un plan gratuito capaz de analizar 500 URLs en 1 análisis para un dominio cualquiera.
A día de hoy César Aparicio es e encargado de realizar algunos videos en Youtube explicando el potencial y cada uno de los apartados que tiene esta tool.
Sí es cierto que de forma general está pensada para usuarios avanzados, pero este tipo de documentación la acerca a cualquiera con ganas de mejorar la visibilidad de su proyecto en buscadores.
He intentado colocar los videos importantes que sevan publicando de la herramienta, e iré actualizando el post.
Por tanto, os dejo un tutorial genérico de la herramienta:
Y otro vídeo general, aprende a usar Safecont en 15 minutos: https://youtu.be/5-ENrqCaYgA
Prueba Safecont Gratis
Lo primero a remangarse… ¿no la habéis probado? Pues mis plegarias han sido escuchadas y ya han abierto un plan gratuito de Safecont con 1 dominio y 500 URLs para jugar con lo que nos de la gana.
Ya me irás contando qué te parece…
Integración de Safecont con Google Analytics
Esta opción es de las últimas que se han implementado, y una de las preguntas que yo mismo les hice el día de su presentación. Por fin, está integrado en la herramienta.
Los inicios de Safecont
Hasta el momento todo análisis de calidad de contenido se ha realizado por humanos, por todos esos SEOs o no SEOs que hemos analizado los problemas de una web, y gracias a Safecont también vamos a poder contar con la inestimable ayuda de las máquinas.
Cuando en Safecont empezaron a trabajar en la herramienta, su idea inicial era:
“Vamos a hacer un algoritmo en el que le des un contenido (texto, imágenes vídeos…) y vamos a conseguir gracias a la Inteligencia Artificial (Machine Learning) saber si es contenido de calidad o no.”
Rápidamente se encontraron con que en la comunidad académica, incluso científica, esto es algo así como el Santo Grial. Es casi imposible al tener un solo documento poder evaluar si tiene mucha o poca calidad, siempre es necesario la comparación, comparar entre un grupo de documentos para poder saber si uno es mejor que otro. Para un determinado tema, necesitas siempre tener varias fuentes para poder decidirlo.
Entonces al final acabaron trabajando en un enfoque completamente distinto, se centraron en detectar si tiene o no tiene esa calidad. Para eso, necesitaron irse un poco a los fundamentos de todo esto.
La llegada de Google Panda
Muchos vivimos esa época en vivo con nuestros proyectos y nunca hemos sabido determinar si se notó mucho o no se notó tanto en el mundo entero. A partir de esa primera fecha de Panda se han sucedido varias actualizaciones a lo largo del tiempo, pero se ha documentado que el Panda inicial afectó al 12% de todas las búsquedas, que no es que afectara al 12% de todos los sitios web, ha afectado a mucho más del 12% de todos los sitios. Este algoritmo o filtro, como lo queramos llamar, afectó al 12% de las consultas del buscador, donde en cada una de ellas se muestran muchísimos sites.
Muchos sitios web fueron perdiendo tráfico Panda a Panda sin saber qué hacer… muchos sites perdieron más del 90% de tráfico.
Cuando se lanzó el primer Panda fue una auténtica conmoción para mucha gente que trabajaba en Internet y tenía negocios con ese tipo de contenido que no le agradaba al algoritmo. Imaginaros una empresa como Hubpages (una de los ejemplos insignia del primer paso de Panda) que tenía cientos de trabajadores… mucha gente tuvo que ser despedida, no quedó otra solución. Al poco tiempo consiguieron remontar un poco al pasar ese “thin content” que tenían en las fichas de usuario (cada usuario podía escribir su contenido ahí y generaba el sistema una URL para él donde aparecía solo lo que ese usuario había publicado) a un subdominio. Esta una de las estrategias más clásicas que se han utilizado para salir de penalizaciones por contenido en el buscador. Pero luego fue refinándose el algoritmo y este tipo de sitios si no se hacía mucho por cambiar, seguían perdiendo tráfico orgánico actualización a actualización.

El impacto fue grandísimo.
Otros afectados consiguieron recuperar algo de visibilidad cambiando un poco a qué se dedicaban y cómo trabajaban sus URLs o sus contenidos.
Y ahora algo de cultura general: ¿Qué es machine learning?
Safecont al rescate
Y entonces llega Safecont, al rescate, intentando ayudar tras más de 2 años en los que no habían dado con una posible solución a este problema.
Vamos a ver cómo nació Safecont y cómo funciona por dentro.
Safecont es un sistema de Machine Learning que analiza la información que está contenida en las páginas web que analizan mediante un sistema de Big Data. Esto les permite hacer crecer o decrecer la infraestructura con la que cuentan en función de la cantidad de trabajo que se requiera.
Tecnologías utilizadas por Safecont
Para realizar este trabajo, la herramienta emplea una serie de tecnología de Big Data que están siendo bastante utilizadas actualmente.
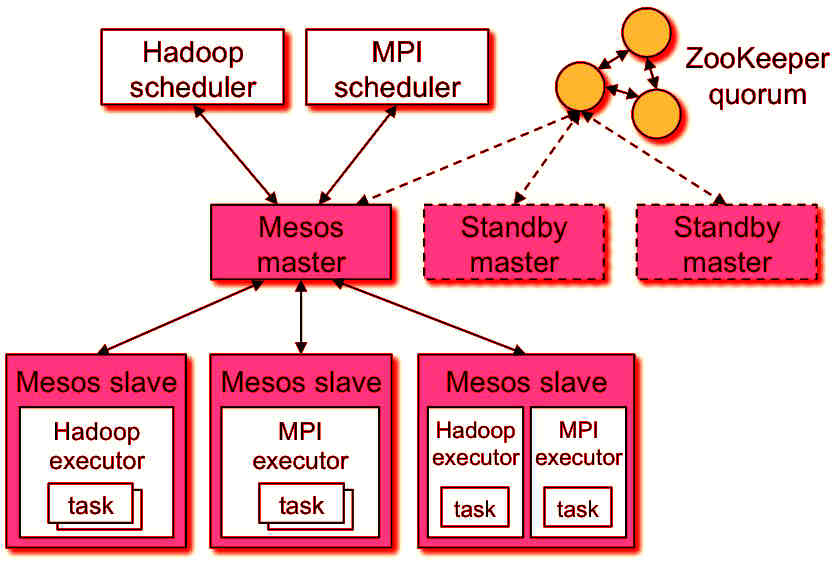
Mesos
El software más importate es Mesos, un scheduler de tareas que te permite gestionar los diversos nodos que tienes en un sistema y te permite ejecutar tareas de forma fiable, es decir, que si uno de esos nodos de entre todos los que tengas te falla el sistema se encarga de relanzar los procesos de ese nodo en otro sitio automáticamente, sin que te tengas que preocupar. Por este motivo las tareas que se ejecutan en Safecont siempre van a terminar, 100% garantizado.

Entonces esto es un esquema de cómo puede ser una estructura normal de un sistema con Mesos, donde tenemos un nodo maestro que se encarga de aceptar tareas que se piden en la web y va analizando en los diversos nodos clientes que tienen, los cuales ejecutan el software con el que funciona Safecont.
Spark
El principal motor para el procesamiento de datos a gran escala en Safecont es Spark, una implementación de MapReduce que les proporciona diversos algoritmos de Machine Learning ya implementados además de un crawler que han optimizado ellos mismos y una base de datos no relacional que se encarga de almacenar toda la información después de procesarla.

¿Queréis saber cómo es el proceso de machine learning en Safecont?
Clústers en Safecont
Vamos ahora a la parte práctica de la herramienta, a ver para lo que realmente nos puede servir. Hasta ahora hemos comentado un montón de conceptos. Los dos conceptos más extraños que vas a encontrar en la herramienta son:
- PandaRisk: la probabilidad de tener una penalización en todo el dominio
- PageRisk: la probabilidad que una URL tiene de ser penalizada
Vamos a ir con la parte de clústers, un término matemático que en probabilidad lo podríamos definir como grupos o agrupaciones.
¿Por qué Safecont trabaja con clústers? Porque trabajan con un montón de datos y deben agruparlos. Se hacen clústers de URLs que tienen un mismo patrón. Han introducido los algoritmos de Machine Learning, han detectado los patrones que pueden tener o no tener, los que puede considerar Google que son positivos, negativos o punibles y los han clasificado en la herramienta. Así trabaja Safecont para facilitar el trabajo a los que la usamos.
Safecont se encarga de coger toda la página web, sacar todos esos parámetros que en un Excel normal sería imposible de trabajar, y lo resumen fácilmente en su interfaz. Reparten las URLs en clústers y nos dice cosas como: hay 1212 URLs con una similaridad cercana al 100%. Si como SEO quiero arreglar el dominio de mi cliente, ¿a dónde voy? Voy directamente a las que sé que tienen una similaridad mayor, el resto sé que no me van a traer problemas, no las toco.
¿Que haya mucha similaridad semántica entre URLs significa que nos vaya a penalizar Google directamente como si fuera el único factor que va a tener en cuenta? No. Por eso, aunque tengamos una similaridad alta en muchas URLs, podríamos tener una peligrosidad en ese clúster de URLs no muy alta. En cualquier caso, sería algo que tendríamos que revisar más a fondo.
Video sobre la pestaña Clústers
Clústers de Pagerisk
Esta es una funcionalidad bastante interesante. Coge todas las URLs que han encontrado en nuestro dominio y nos las organiza en grupos por probabilidad de ser penalizadas por Google.
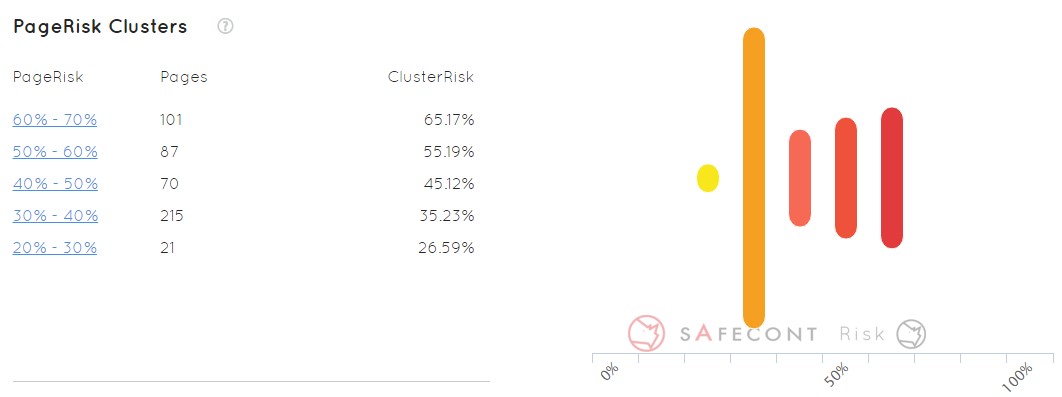
Si yo analizo un dominio no voy a tener que ir URL a URL mirando todos los patrones y todo lo que pasa (siempre que sea capaz de hacerlo), sino que voy directamente a las 101 páginas que vemos en el ejemplo anterior que tienen mayor probabilidad de ser penalizadas. Luego al siguiente clúster, y así paso a paso voy corrigiendo mis problemas.
Video sobre la pestaña Risk
¿Qué podemos sacar de provecho de Safecont?
Detectar la similaridad
La similaridad no se refiere al contenido duplicado, es algo parecido. La duplicación equivale a que detectara contenidos exactamente iguales, literales, pero no es el caso. Por poner un ejemplo: contenidos reescritos por un redactor el sistema de Safecont sería capaz de detectarlo. Esto es bastante importante porque en una web se mezclan textos de contenido con cabecera, footers y otras cosas variables que podrían hacer que no se pudiera detectar si fuera simplemente contenido duplicado.
Tenemos varias formas de estudiar la similaridad de contenido. Se puede estudiar mediante análisis de N-gramas, steaming, frecuencias de esa palabra respecto a la frecuencia que tiene esa palabra en todo el dominio, distancia de levenshtein… hay un montón de patrones.
Imaginemos que la imagen siguiente es un dominio. Un 50% de ese dominio es contenido original, no tiene nmingún tipo de duplicación ni similaridad con las otras páginas de ese dominio, y sin embargo la otra mitad tiene algún tipo de similaridad, igual es copia directa (cuanto más oscuro más copia de la parte original) o bien tiene algún índice de similaridad.
 ¿Cómo se ve en Safecont? Así…
¿Cómo se ve en Safecont? Así…

Como se puede ver, la información está ordenada por clusters (agrupaciones de URLs). En este caso se agrupan por el nivel de similaridad, por el nivel de peligrosidad que tiene cada grupo de URLs. Aquí vamos del 90 al 100 es un cluster, del 80 al 90 es otro… y en el gráfico de la derecha el tamaño de la barra nos da fácilmente a entender qué de grande es ese grupo de URLs respecto del total del dominio. El color indica el nivel de peligrosidad, de verde a rojo como si de un semáforo se tratara.
Cuando quieres limpiar un dominio rápidamente puedes ver qué es más prioritario, en este caso los dos primeros cluster de 90-100 y 80-90. A su vez podemos ver dónde se concentra más número de URLs peligrosas. Por encima del 50% de similaridad lo ideal sería que lo corrijamos lo antes posible. Son páginas que a priori no sirven para nada, que ya tienen ese contenido dentro del dominio en otra parte. Le estamos haciendo a Google trabajar el doble, que en vez de una tenga que crawlear dos o N páginas iguales. Hemos de entender que a priori todo lo que sea trabajo para Google o complicarle las cosas es malo para SEO.
Si hacemos clic en cada cluster, vamos a tener no solo la información en más detalle, sino el listado de URLs concretas, con el porcentaje de similitud de cada una de ellas, la posibilidad de ver su información detallada, el % de duplicación externa, el PageRisk, y la capacidad de exportarlo todo a CSV para poderlo trabajar paso a paso de forma externa.
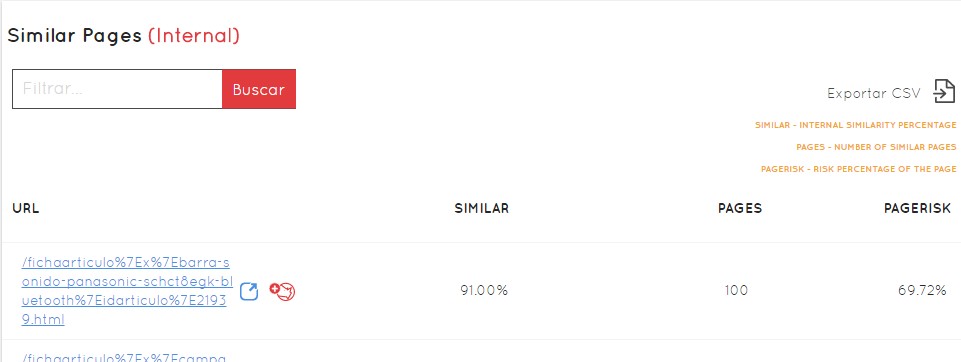
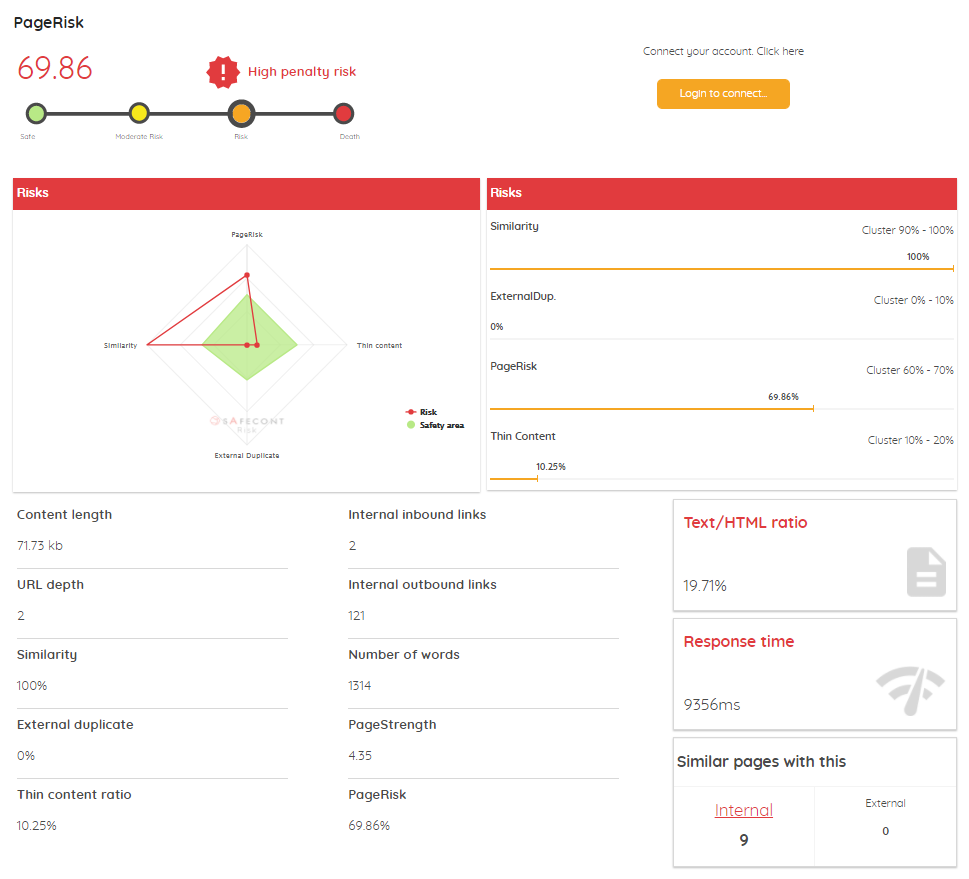
En cada URL veremos siempre dos iconos, uno azul para ir directamente a esa URL en el navegador y otro rojo para ir a la ficha de Safecont de esa URL concreta, y ver:
- Gráfico de peligrosidad comparando los 4 factores principales de la herramienta: Similaridad, PageRisk, Thin content y contenido externo duplicado, con los datos concretos de cada uno de ellos en porcentaje.
- Tamaño del contenido
- Enlaces internos
- Enlaces externos
- Profundidad
- Número de palabras del contenido
- Fuerza de la página (algo similar a lo que sería su PageRank)
- Texto / HTML ratio
- Tiempo de respuesta
- Número de páginas similares internas y externas
- TFIDF del título y un análisis del mismo
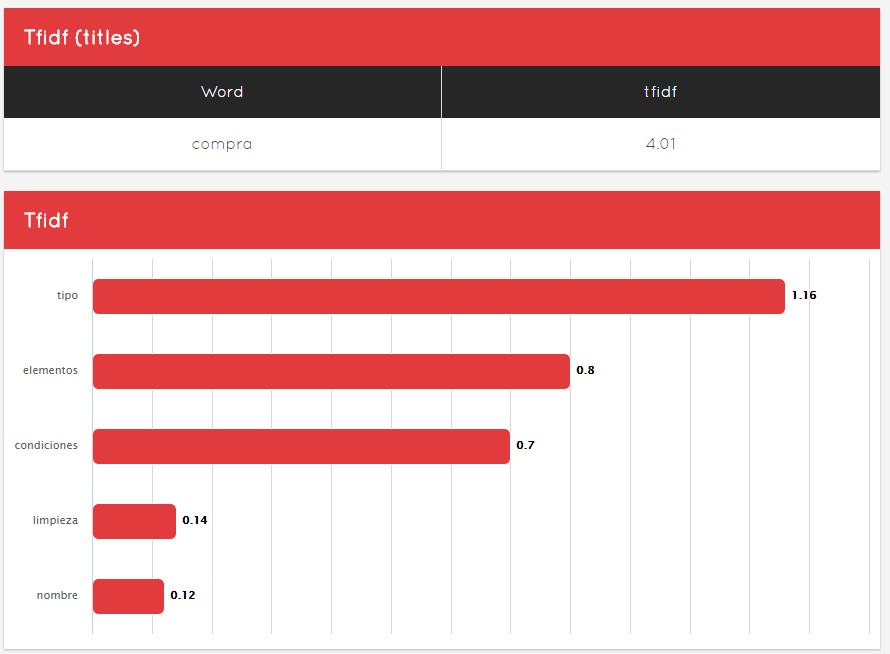
Video sobre la pestaña Similarity
Detectar duplicados externos
La herramienta dispone de otra pestaña en la que podremos revisar duplicados externos. Estos duplicados están a la orden del día en Internet, en resumen sería la copia de contenidos de otras fuentes. Por ejemplo, grandes universidades utilizan este tipo de tecnología para detectar plagios en las tesis doctorales de los alumnos. Empresas, editoriales, revistas… el contenido duplicado es muy común, y es la principal preocupación de muchas personas que se ganan el pan generándolos.
¿Cómo vemos esto en Safecont? Es parecido a la similaridad, con sus cluster de URLs correspondiente.

Debajo tenemos de igual forma que en la similaridad, las URLs listadas, y podremos ver cuáles son las páginas que tienen ese contenido duplicado, ya sea porque tú les has copiado a ellos o porque ellos te han copiado a ti. En el ejemplo de arriba todo está en verde y no tenemos ni una sola URL en peligro.
Es importante saber si alguien te está plagiando el contenido, por si quieres denunciarlo o tomar cualquier otro tipo de acción, hay muchas personas interesadas en esto y Safecont te ofrece cada URL que te ha copiado, el estracto y dónde.
Detectar el Thin Content
¿Qué es el thin content? Es muy difícil de definir. A priori es contenido muy corto, en resumen si en una página tengo poco texto directamente podríamos estar hablando de thin content.
Puede ser… es posible… Pero hay ciertas páginas (por ejemplo si buscáis “alarma” veréis que los primeros resultados son páginas sin apenas contenido en texto, o si buscáis el tiempo es muy probable que sencillamente encontremos resultados que nos ofrecen iconos con lluvia, sol o nubes) que devuelven algo concreto, resolviendo una necesidad de los usuarios sin contenido escrito… y esto no es thin content, es el contenido que quiere ver el usuario cuando llega a esa página (quiere un sistema que le sirva de alarma o quiere conocer el tiempo que hará el fin de semana en su localidad).
¿Cómo detectar si un contenido es thin content? Safecont lo resumen en 6 puntos:
- es trivial
- es contenido redundante
- es contenido escaso
- no resuelve una necesidad
- tiene mala calidad de escritura
- está fuera del tema de la web
- está desfasado
En la interfaz de Safecont siguen la misma estructura que los puntos anteriores para facilitar el uso de la herramienta en este apartado.
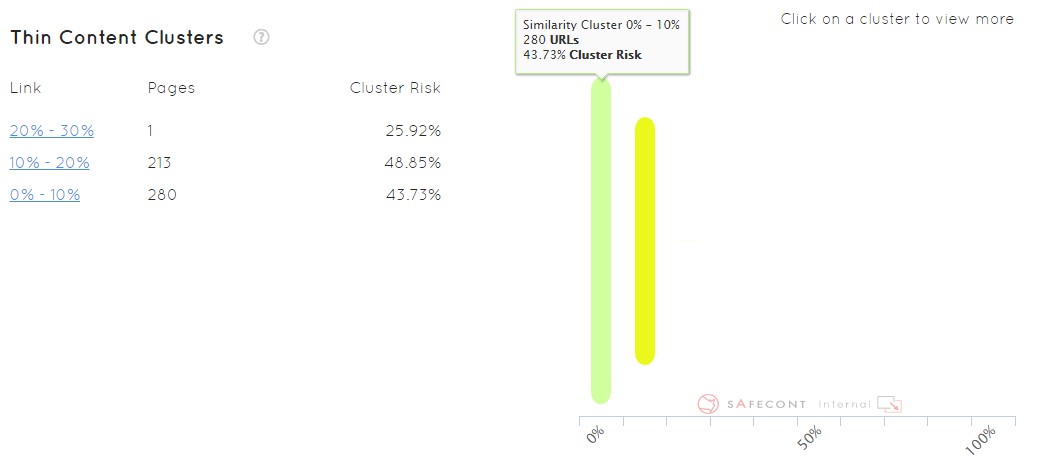
Como podemos ver en la imagen, podemos pasar el ratón por cualquiera de las barras y observar que nos aparece información por cada clúster, con suporcentaje de similaridad, el número de urls y la peligrosidad de penalización. Como siempre, podemos hacer clic y ver debajo todas las URLs que lo componen para trabajar directamente sobre ellas.

Análisis semántico
Safecont ha introducido un apartado de semántica donde poder saber de un simple vistazo cuáles son las palabras más relevantes dentro del sitio web, un contraste de la palabra clave con todas las URLs del resto del dominio.
Podemos ver en la interfaz una representación tridimensinal (aunque Safecont trabaja con 1000 dimensiones) para poder verlo fácil.
En esta caja en tres dimensiones, podemos ver puntitos que equivalen a temáticas. Cuanto más lejanos entre sí, menos tienen que ver. De esta manera podemos ver si las temáticas que trabaja un dominio están relacionadas unas con otras o no.
Como vemos, la temática de este sitio parece no estar muy relacionada entre sí, todos los temas de los que habla son bastante dispares (excepto los puntos azules). Un exceso de similaridad semántica también podría ser perjudicial, no en todos los casos, para ello hemos de analizarlo en profundidad.
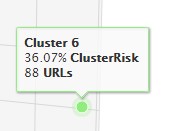
También podemos encontrar rápidamente clúster temáticos que no tenemos ni idea de por qué se separan tanto del resto (como en este ejemplo el verde) y analizar si la estructura es incorrecta y no corresponde con lo habitual en mi sitio web. Puedo pasar el ratón por encima de él y me dirá a qué cluster de URLs pertenece (en el ejemplo al cluster 6), cuántas URLs tiene (88) y que clusterRisk supone (36,07%)
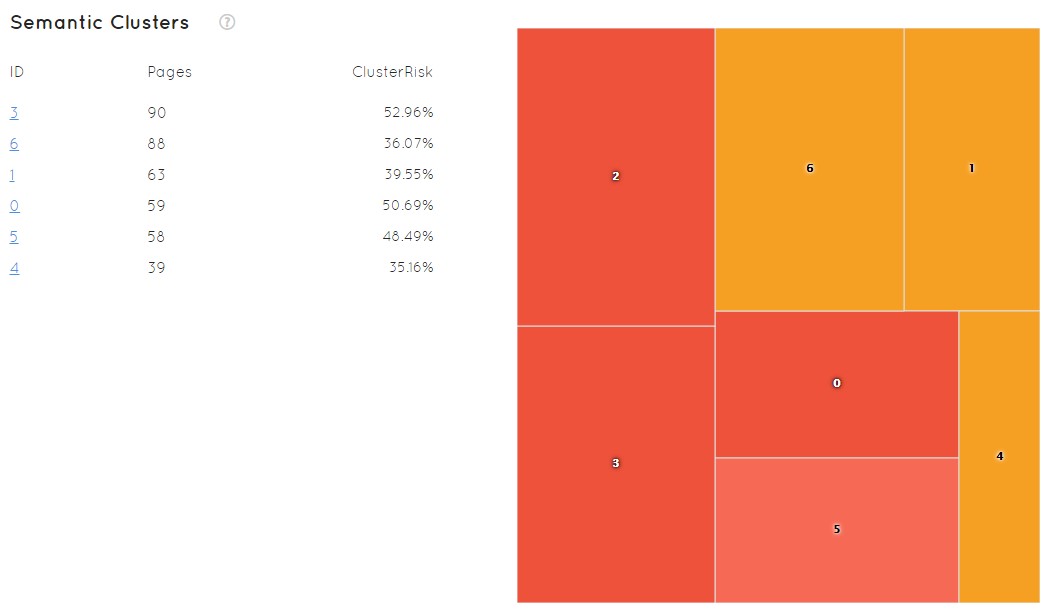
Sabiendo el número de cluster, en la misma pantalla tenemos otro gráfico que nos permite verlo en profundidad. El ID nos permite reconocerlo, nos muestra el número de páginas y el clusterRisk resumidos para cada uno de ellos.
A su vez, aparece un gráfico que nos permite ver rápidamente el estado de mi sitio donde el tamaño de los cuadros y el color dan rápidamente a entender los problemas que pudiera tener y la situación en la que me encuentro. Rojo implica más peligro, naranja menos… En este ejemplo no tenemos ninguno verde que sería lo óptimo, lo que quiere decir que no tenemos agrupaciones semánticas que estén a salvo, a priori, de ser penalizadas.
Para seguir profundizando puedo hacer clic en el clúster 6 y comenzar a trabajar. Veremos todas las URLs que tenemos en ese clúster. Veremos el porcentaje de similaridad que tiene (lo similares que son esas 88 URLs que estaban incluídas en ese clúster que podría considerar peligroso), me va a decir el peligro que tiene de ser penalizado por Google o no ser penalizado y luego nos mostrará todas las URLs.
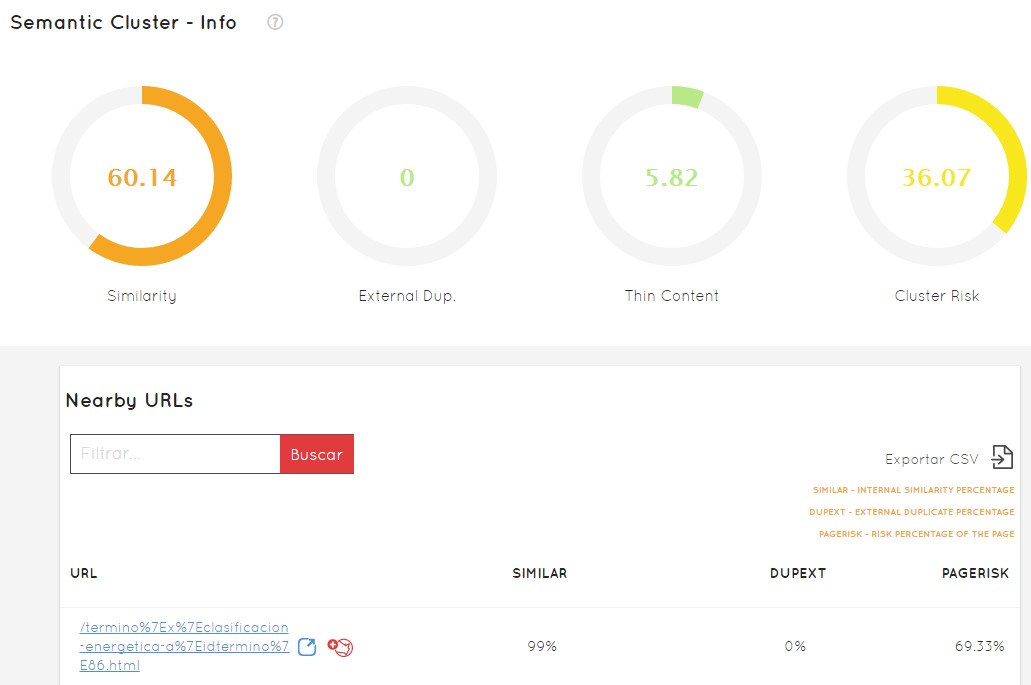
Solo a golpe de clic vamos a conseguir ver qué patrones son los que me están perjudicando mi proyecto. Hacer esto a mano, sin que alguien te lo muestre así, podría ser trabajo de meses o de suerte… y en un mundo competido como este no podemos ya permitirnoslo.
Arquitectura web
A este apartado vamos a poder sacarle mucho partido como ahora veremos.
Hablemos de sitios grandes o pequeños sería indiferente, evidentemente cuanto más grande es el sitio y más factores queramos analizar, más complejo es el asunto.
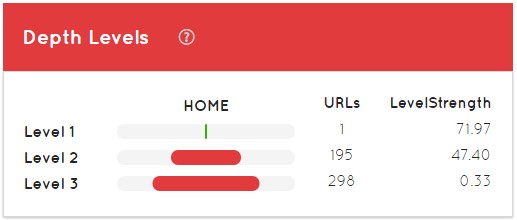
Lo primero que nos aparece es el nivel de profundidad del sitio web, con la home como nivel 1, categorías, subcategorías, etc… Cuanto más tiempo suele tener una web, generalmente las estructuras van variando, van apareciendo nuevos niveles de profundidad, etc…
PageRank calculado
El LevelStregth es lo que nos dice el “PageRank” que tiene cada nivel de profundidad. A modo de lectura de ejemplo, a la hora de posicionar esas 298 URLs que tenemos en nivel 3 nos va a resultar bastante más complicado que posicionar las otras 195 que tienen un 47,40 de LevelStrength.
Generamente, la home debería de tener un LevelStrength de 100, pero al ser un análisis parcial en la imagen anterior no me aparece como tal. Lo correcto además es que el segundo nivel tuviera también otro 100. Si el segundo nivel tiene menos de eso, quiere decir que mi enlazado interno está mal realizado, tengo problemas, no está llegando correctamente el link juice de la home hasta la siguiente URL de nuestro sitio, máxime cuando estamos hablando de nivel 1 a nivel 2.
En un supuesto nivel 10 de profundidad podríamos tener 0,0X, son cuestiones bastante complicadas de resolver pero Safecont es un facilitador claro de las mismas.
Como vemos en la imagen de antes, volvemos a tener colores para intuir rápidamente lo que está bien o debemos corregir. Podemos pinchar y acceder a la información de ese nivel y el listado de URLs que lo forman. Mirad:
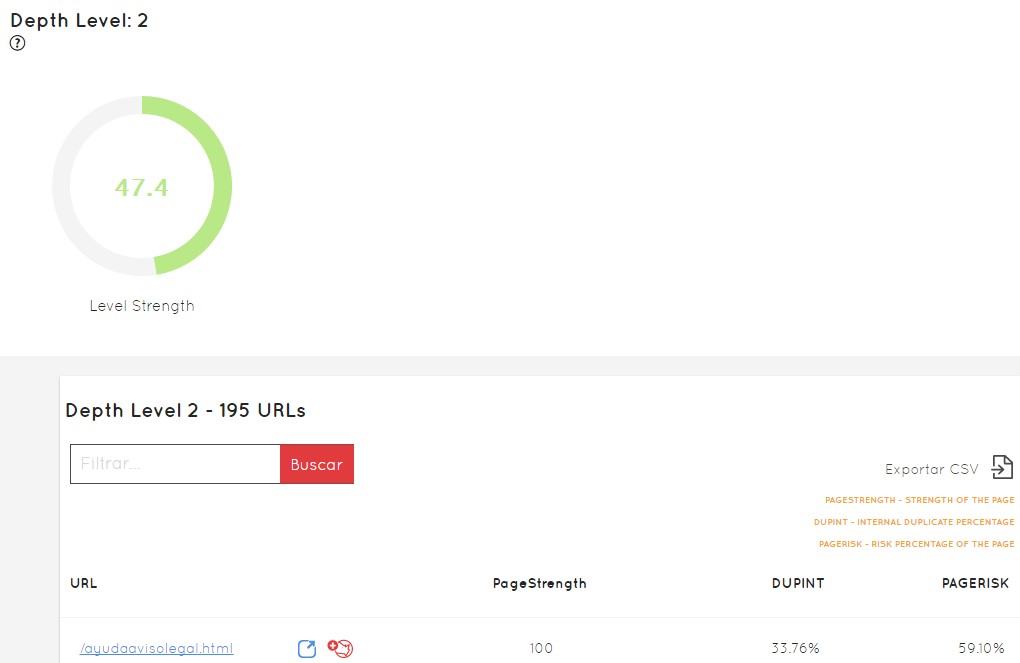
El PageRisk de cada URL
Lo que yo debo de intentar optimizar es toda la estructura de enlaces dentro de mi sitio web.
¿Cómo lo vamos a hacer? Debemos analizar URL por URL.
Lo primero que vemos en la URL de ejemplo es que esa URL tiene un duplicado interno del 33,76%, lo que significa que ya tengo otras URLs con ese contenido duplicado o muy similar… Puedo pinchar en ella y ver qué tiene para corregirla:
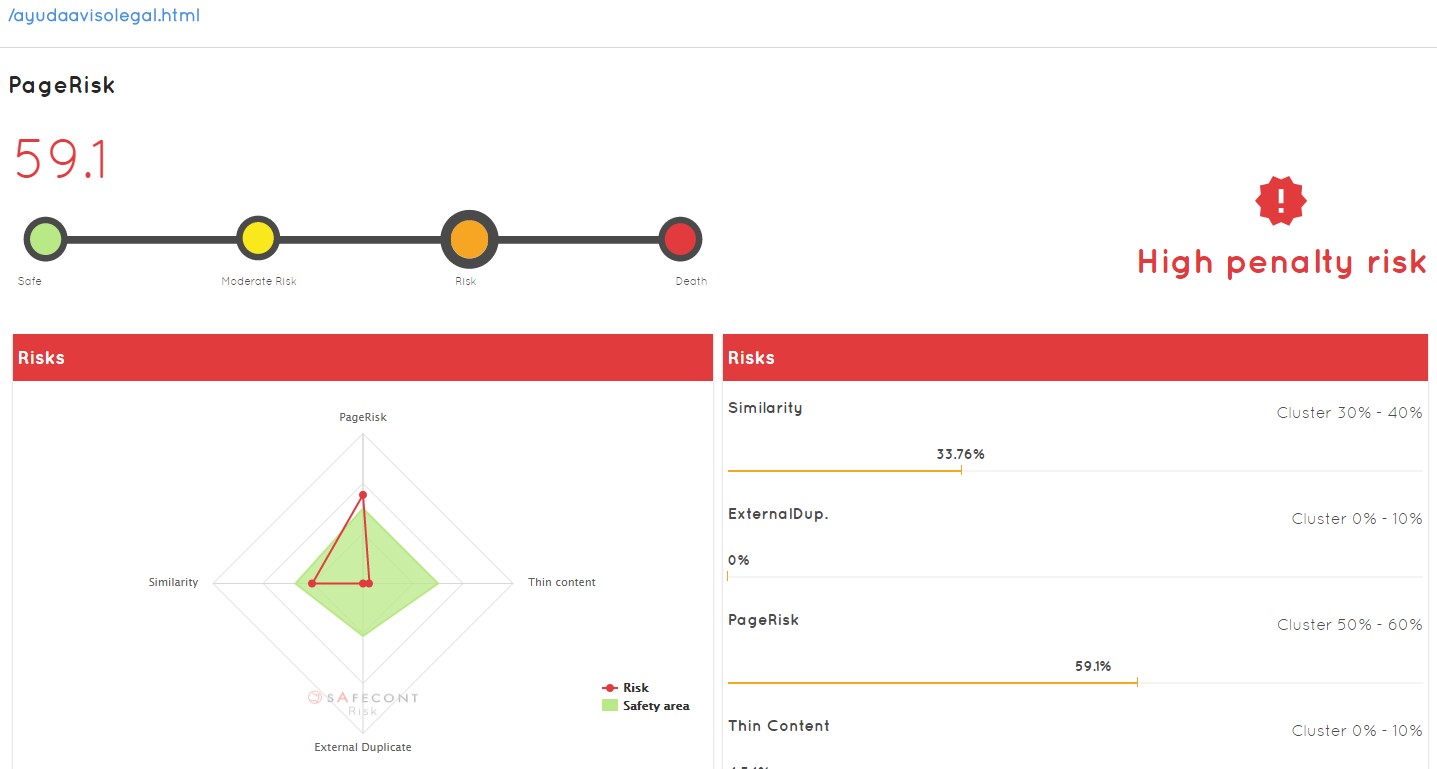
Rápidamente vemos que tiene un alto índice de similaridad (pero dentro de la parte segura) y un alto pagerisk, por lo tanto, a corregir. Puede ser que no solo esté enviando enlaces a sitios que no son correctos, sino que además puede que lo esté haciendo a URLs que son contenido duplicado. A golpe de clic ya sé qué páginas de las que tengo en niveles inferiores están recibiendo enlaces de un nivel superior, enlaces que estoy perdiendo y que encima me están llevando a sitios con los que probablemente Google me pueda penalizar después. Además de que esas páginas a su vez tengan de nuevo enlaces a más páginas que están duplicadas, contenido no optimizado, etc…
La fiabilidad que los chicos de Safecont han conseguido está en torno al 82%… algo que de forma manual no podríamos conseguir a priori en ninguna de nuestras decisiones.
Hubs y Authorities
Por otro lado, podemos ver un gráfico dentro de la pestaña de arquitectura con Hubs y Authorities.
Hub: es un sitio bueno donde me tienen que poner un enlace para que a mí me llegue autoridad
Authority: es un sitio donde yo pondría contenido porque es muy relevante a los ojos de Google
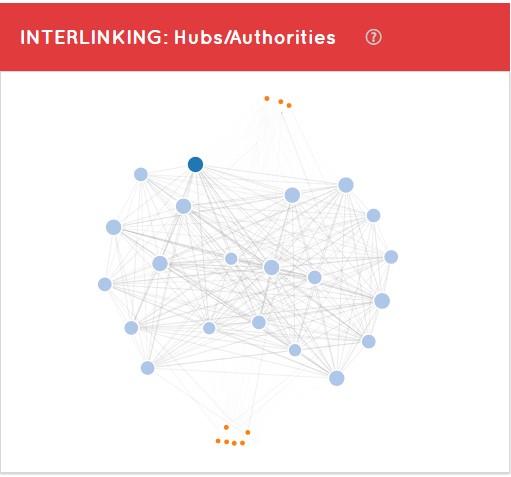
Este gráfico viene acompañado de una tabla de Hubs ordenadas de mayor a menor por su HubValue
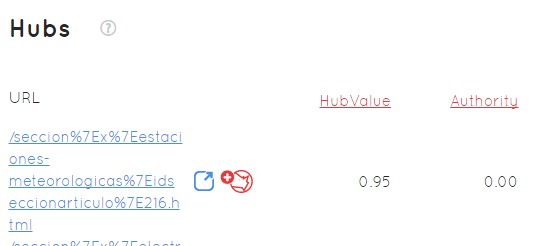
Si quiero poner un enlace en alguna URL concreta, a mayor valor Hub más potente va a ser ese enlace. Pero lo que me está diciendo el otro valor en este ejemplo es que esa URL no es un buen sitio para publicar contenido porque tiene poca Auhority a la hora de posicionar.
Los Anchors de los enlaces internos
En el último apartado de la pestaña de arquitectura vemos qué ocurre a nivel de Anchor con los enlaces follow internos de nuestra página.
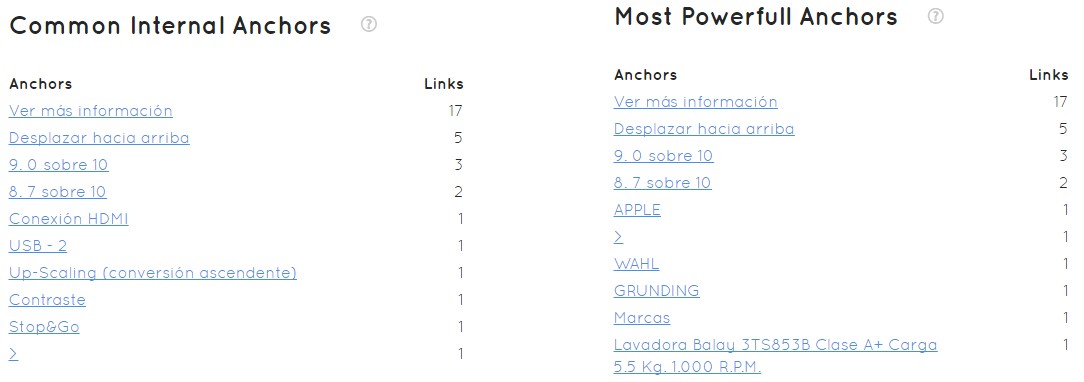
Igual que tenemos que optimizar la cantidad de enlaces que tenemos, también debemos de intentar optimizar el anchor apropiado para posicionar determinadas landing o categorías, subcategorías dentro de nuestro sitio web.
Vemos que lo más común es “Ver más información”. Esto no es lógico dado que no es nuestro negocio, pero tampoco ninguno de los siguientes en una web que se dedica a la venta de electrodomésticos. Estas keywords no son algo que nos interese posicionar.
Por otro lado, vemos que el anchor que más relevancia da a las páginas, también es “Ver más información”, 17 links… es el más común y encima no me vale absolutamente para nada. El anchor más común no tiene por qué ser el anchor más poderoso, dado que cada anchor y cada enlace tiene un nivel de PageRank, y Safecont lo calcula y nos dice: este anchor APPLE está en estas URLs concretas, tiene 0,259 de fuerza y se ha utilizado una vez.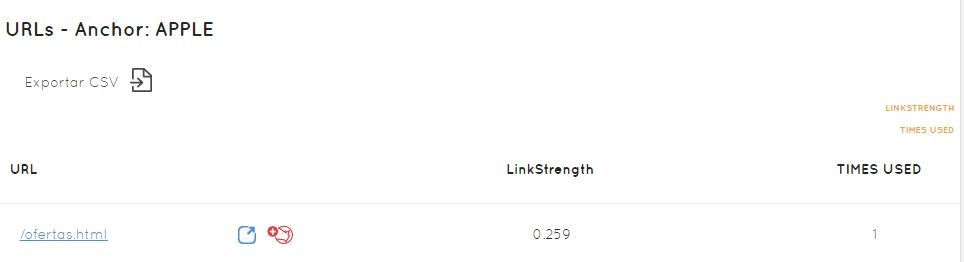
A partir de aquí puedo determinar:
- en qué Hub tengo que poner determinado enlace
- en qué Authority tengo que poner determinado contenido
- tengo “Ver más información” repetido en exceso 17 veces con un enlace follow que no estamos optimizando como debemos la relevancia de los anchor text
- hemos visto que en muchas ocasiones estamos enviando enlaces a sitios que son contenido duplicado y son perjudiciales para nosotros.
Páginas en Safecont
Muy fácil, nos aparecerá un listado de todas las páginas que tenemos, indicando cuál es la más perjudicada y posiblemente penalizará nuestro sitio, hasta la que mejor está. Esto no quiere decir que la última esté bien ni que la primera sea mala, todo dependerá del dominio sobre el que estemos trabajando.
En la interfaz, esta pestaña nos ofrece los determinantes básicos que Safecont ha decidido mostrarnos. Tras esto hay un montón de cálculos sobre parámetros que no han incluído para resumirnos las características más llamativas.
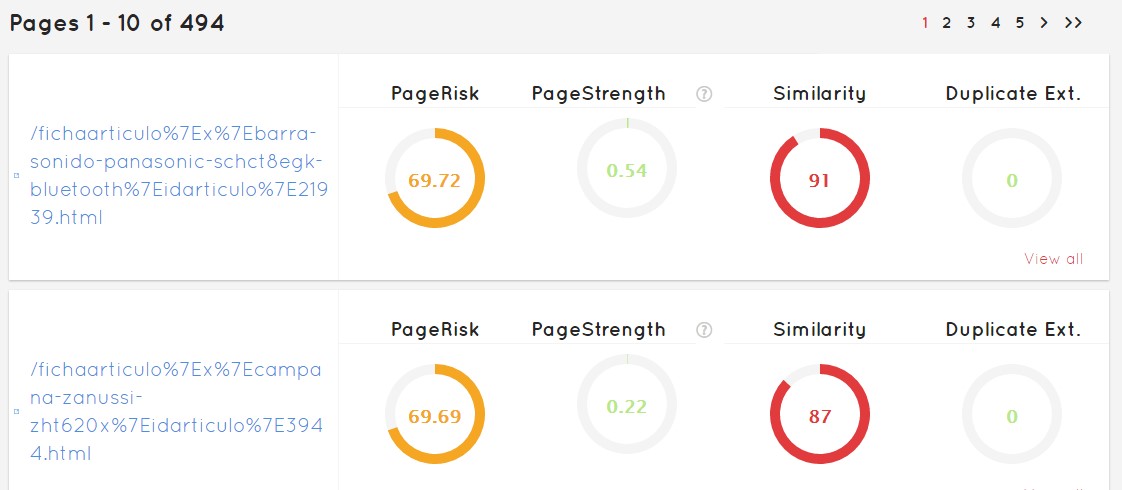
Vemos que rápidamente me puedo ir a aquellas que tengan más problemas, y corregir de forma ordenada los problemas del sitio web que desee optimizar.
CrawlStats de Safecont
Actualización 8 de septiembre de 2018
Esta funcionalidad salió a la luz el 3 de septiembre de 2018.
De un simple vistazo, podemos ver:
- las páginas únicas de nuestro sitio web
- Las páginas no indexables
- Las que no nos ofrecen un código de estado 200
- Las que superan el límite de rastreo
Como siempre en Safecont, las podemos exportar en CSV para trabajar con ellos. Además, nos ofrece un índice sobre la facilidad de crawlear el sitio a un bot, que denominan Crawl Health Score.

En un segundo panel, nos ofrece una comparativa con el crawleo anterior, para ver diferencias tras el trabajo realizado o por cambios de estado del site.
A modo de resumen, en un tercer lugar, aparecen 3 cajas mostrando de un simple vistazo:
- Las URLs no indexadas (no son las indexadas en un buscador, sino aquellas que sabemos perfectamente que no van a indexar, como son las redirecciones)
- Las que no ofrecen un código de estado 200: errores 4XX y 5XX
- URLs únicas y aquellas canonicalizadas
Por último, nos ofrecen un gráfico que particularmente a mí me gusta bastante, donde podemos ver las URLs crawleadas por nivel.

A su vez, de cada nivel, podemos ver las URLs que no tienen código 200, las no indexables, las únicas y el Score o índice que antes comentábamos, de ese nivel en concreto. Bastante accionable, ¿no creéis?
La Página principal de Safecont
Como colofón de todo este análisis, quiero hablar de la página de inicio de Safecont. De una forma clara nos va a mostrar varios problemas tras el análisis:
- Principales problemas de nuestro dominio
- Probabilidad de ser penalizados por Panda

Aquí como vemos el número es 61,57. No es un porcentaje de penalización, es un número de 0 a 100 puntos posibles. De 100 puntos que pudiera tener un dominio, ¿cuántos tengo yo? No es una probabilidad.
- Un gráfico de la situación del dominio por los principales factores de la herramienta y su “área de tranquilidad”

- Clústers de URLs y URLs concretas con mayor índice de peligrosidad
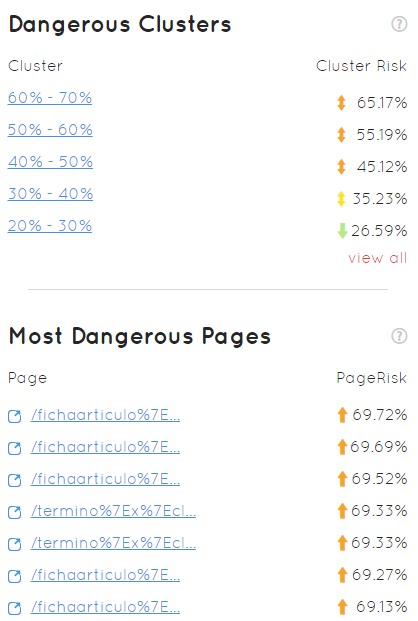

En definitica, la idea es acabar con un 35% de probabilidad de que nos penalice Panda, y no con un 65% que suele ser la media habitual de lo que Safecont suele encontrar en sus análisis habitualmente.
Cómo arreglar una web con Safecont
Una vez hemos analizado la web con Safecont, hemos visto todo lo que está mal, los clúster, las URLs, etc… y ya sé lo que sucede, debemos ponernos manos a la obra.
¿Cómo arreglo todos los problemas de mi web?
El contenido de baja calidad en algunas partes de mi sitio web puede impactar sobre el ranking de toda la web, y por lo tanto la eliminación de páginas de baja calidad, la fusión, mejora de contenido en páginas individuales, o mover las páginas que no tienen calidad suficiente a un dominio a parte, te puede ayudar a que Google clasifique y valore mucho mejor el contenido de tu site.
Metodología de trabajo con Safecont
En su presentación, Safecont presentó esta metodología para trabajar con su herramienta:
- Primero separamos la basura, las URLs que Safecont nos está diciendo que no son buenas, que no tienen un grado de calidad bueno, que pueden ser penalizables, y las separamos por tipología de página: si son categorías, sin son fichas o si son consultas…
- Estudiamos qué porcentaje representan cada uno de esos grupos en el total de todas las páginas malas. Ejemplo: el dominio tiene 50K y tengo 10K malas, y dentro de esas malas las categorías son 1K. Vemos qué porcentaje representa dentro de ese total de malas, y sacamos a su vez el porcentaje sobre el total de páginas del dominio, en el ejemplo de las 50K.
- Sacamos el tráfico orgánico de esos tipos de páginas. Ejemplo: cuánto tráfico orgánico llega a categorías, o a fichas de producto o a la home, etc…
- Comparamos el riesgo de penalización del dominio en un supuesto eje X imaginario y en el eje Y el número de URLs que tenemos. Tendríamos una línea imaginaria que determinaría la penalización Panda, pero si reduzco el número de URLs malas, el riesgo se reduce.
- Evaluamos los cambios que se vayan a realizar. ¿Cuánto tráfico voy a perder por la limpia? Por ejemplo si vas a eliminar URLs, vas a redireccionar, lo que consideres… probablemente te suponga una pequeña o una gran pérdida de tráfico.
- Evaluar cuánto tráfico has perdido ya por Panda Update si es un dominio antiguo y ha sufrido penalización. Si es nuevo, realmente no sabes cuánto estás perdiendo por esa penalización por culpa del algoritmo de calidad de Google. Si el tráfico que vas a perder es inferior al que ya has perdido o estás perdiendo, adelante con limpiar.
Lo siguiente que debemos hacer si vamos a continuar es seleccionar las diferentes tipologías de página y decidir qué hacer con ellas.
Soluciones a los problemas detectados
Posibles soluciones (cada una apropiada a un tipo de página o problema):
- Redireccionamiento 301: si tenemos varias páginas que son iguales. Eliges la que tu decides que quieres posicionar y el resto las redireccionas a ella.
- Meta noindex: por ejemplo si alguna página pese a que tenga un contenido que Google pueda considerar de mala calidad… puede ser importante para el usuario, y es importante que aparezca en la navegación de tu site y el usuario llegue a ella.
- Con el fichero robots.txt: También puede ponerle un Disallow a nivel de robots.txt. Hay muchos que quizá no podamos definir a nivel de página la etiqueta robots, y podemos hacerlo desde ahí, incluso en masa.
- Meta canonical: apuntar todas las URLs que podrían ser peligrosas y similares a otra, meter un canonical para decirle a Google que esa es una versión que yo tengo por otros motivos y quiero que la que apuntes es esta.
- Unificar contenido: si tenemos varias URLs con thin content, escasos, pequeños sobre un mismo tema, coger todos esos pequeños, agruparlo y unificarlos construyendo una sola página con todo ese contenido.
- Enriquecer: esto dependiendo del volumen de URLs que tengamos a veces es factible y a veces no. Consiste en mejorar el contenido de una URL, enriquerla con datos nuestros, el contenido que veamos que podría serle útil al usuario, etc…
A partir de un 40% de PandaRisk deberíamos de empezar a preocuparnos.
En la presentación que tuvimos nos mostraron el caso de Emagister, que lleva ya bastante tiempo utilizando la herramienta. Tras perder tráfico desde 2011, han conseguido a día de hoy incrementar el tráfico un 160%, considerando que venían en caída, son datos espectaculares.
Conclusiones
Esta herramienta no sustituye a tu SEO, a la persona responsable de la parte de visibilidad en las búsquedas, sino que es un facilitador. Realmente cuando uno se enfrenta a un caso de penalización o simplemente a un proyecto nuevo, ya sea más grande o más pequeño, es muy difícil encontrar dónde está el problema. Hay cosas que consigues ver fácil pero hay otras en las que es tal el volumen de datos y de información que no lo sabes y acabas en un proceso de prueba y error que te va a llevar meses. Meses no para solucionarlo, sino en darte cuenta de lo que ocurre.
Con Safecont, en pocas horas tras introducir tu dominio vas a ver si tienes problemas o no, qué problemas concretos son los que tienes y dónde. Y a partir de ahí puedes empezar a trabajar, a poner soluciones, y te facilita esa tarea gracias a la clusterización, el seguimiento de parámetros para poder centrarte a trabajar solo en lo que puede ser la peor parte de tu web o la que peor calidad tiene, en vez de trabajar con un gran volumen de URLs sin poder hacer foco.
Por otra parte, recalcar que Safecont no es análisis de Panda solamente. Es análisis de contenido, incluso de anchor text y mejora de la arquitectura. En Safecont utilizan Panda porque es un término que todos más o menos conocemos y manejamos, pero es la optimización del propio sitio en general a golpe de clic.
Turno de preguntas
1. Primera Opinión
Enhorabuena por la herramienta, creo que por fin tenemos una herramienta que nos va a poder dar soluciones, no a corto plazo, pero sí la posibilidad de priorizar. Al final con penalizaciones, tras muchos años de penguins y pandas y conseguir aprender qué son y cómo tratarlas, realmente la herramienta es muy buena para intentar detectar qué áreas son las más afectadas y priorizar sobre qué harías y por dónde empezar.
Tras probar la beta con un proyecto, lo más interesante es la posibilidad de ir saltando de clúster en clúster y priorizar sobre lo que más riesgo tiene, no solamente a nivel general con el PandaRisk, sino con la duplicidad, similitud y arquitectura.
La parte de arquitectura creo que tiene unas posibilidades brutales, porque nos permite mejorar el enlazado interno y nos permite detectar qué páginas se convierten en páginas comodín o páginas que tiene muchísima autoridad. Entonces creo que para proyectos grandes está muy bien pero para proyectos medianos de 20-30K también tiene bastante potencia la herramienta. Nos va a poder permitir, digamos, quick wins por decirlo de alguna manera, y avanzar y empezar a escalar en la recuperación del tráfico si ya nos han penalizado o evitar que nos penalicen. Entonces creo que tiene muchísimo potencial y las integraciones que podáis realizar en un futuro creo que van a tener muchísimo más potencial aún.
Por último, quizá en empresas grandes que tengan un equipo de IT grande o interno, tienen más posibilidades de hacer cosas y de seguir avanzando para salir o mejorar el tráfico, pero a lo mejor en PYMES o sitios más pequeñitos, hace falta esa priorización para ir a esas URLs que pueden hacerte más daño y mejorar esa parte, y a lo mejor el resto no tienes que invertir tantos recursos en trabajar muchas cosas.
La parte de interfaz está bastante bien, es muy intuitiva, reporting PDF para todo el proyecto completo… entiendo que todo esto lo iréis mejorando y lo iréis avanzando. Alguna cosa mala, quizá no mala como tal, pero a aquellos que ya sepan SEO de manera muy avanzada a lo mejor le cuesta menos entender las métricas y los conceptos. Una página de soporte… ayudaría a otros perfiles a aterrizar en algunos conceptos que podrían ser complejos.
2. ¿Similaridad?
Pedro: He visto que la similaridad de contenido a nivel interno está muy bien, pero ¿cómo analizáis los dominios externos?
Safecont: eso lo hacemos con una tecnología propia similar a la de Copy Scape (diría que más potente). La aplicamos tanto para la parte de similaridad interna como externa. Al final podemos saber si un contenido está presente en cualquier otra URL de Internet. Todo Internet es casi imposible, pero nosotros en los test que hemos realizado tenemos un mayor volumen que el que tiene la competencia.
Pedro: ¿La similaridad de contenido externo creéis que ahora mismo está afectando a Google Panda?
Safecont: No, no está dentro de Panda, esto lo explicó bastante Google en su momento. Ellos tenían un algoritmo que se basaba en eso (creo recordar que Scraper update o similar) que simplemente penalizaba sitios que copiaban contenido unos de otros. Luego está Panda, que es otra cosa, evalúa calidad. Lo que pasa es que si tienes un sitio donde tu copias muchos contenidos…
Pedro: claro pero más que “copiado” me he quedado más con la idea que has dicho de similaridad… a nivel general es algo que prácticamente lo hace casi todo el mundo…
Safecont: todo depende de cómo lo reescribas… tu puedes leerte un texto, darte la vuelta y escribir tu versión sobre él… probablemente ahí ni nosotros ni nadie puede llegar a detectarlo, aunque en parte sí. Pero si tú lo que has hecho es coger el documento, cambiar dos frases, cambiar cuatro palabras, poner un par de sinónimos… la herramienta es capaz de detectarlo.
3. Integración con Analytics
Alberto Fernández: lo primero enhorabuena por la herramienta. Está muy bien saber las URLs que están mal, las URLs que… pero por ejemplo una integración con Google Analytics para comparar con tráfico orgánico directamente… yo creo que puede ser interesante.
Safecont: estamos pensando en ello
4. Robots virtual
Alberto Fernández: cuando se os pasa un dominio y tiene por ejemplo 1K millones de URLs, supongo que seguís el robots para saber qué analizar y qué no, content types y cosas de ese estilo para saber qué analizar y qué no… ¿Os habéis planteado un robots virtual interno para decir: quiero esto ahora, pero no el resto, etc… en diferentes análisis?
Safecont: lo tenemos como idea, que el cliente al final pueda un poco filtrar qué partes quiere que analicemos crawleemos y qué partes no.
5. Dominios probados hasta el momento
Alberto Fernández: ¿qué número de dominios habéis pasado ya por la herramienta? Dentro de ese ecosistema de Machine Learning… ¿dónde estamos?
Safecont: la mayoría de dominios que hemos pasado son dominios grandes… El número de urls analizadas va por millones.
Safecont: al final es un proceso de entrenamiento, y nosotros introdujimos dominios hasta conseguir un punto de calidad que consideramos que era el adecuado. La fiabilidad actual es del 82%, eso quiere decir que nuestro algoritmo piensa igual que Google 82 veces de cada 100. De las 18 que quedan, no recuerdo si eran 14 o 15, eran porque nosotros sobrepenalizamos más que Google. Actualmente nosotros podemos ser bastante más restrictivos. No es nada malo, sino que realmente vas a limpiar más de lo que te haría falta para que Google te penalizara.
Este tipo de tecnologías que usamos está al alcance de cualquiera y es absequible, pero entrenar a un algoritmo es muy caro, necesitas muchas iteraciones, muchos datos, mucha información, muchos días procesando… y es la parte crítica.
6. Planes de precios, proyectos únicos recursivos y agencias
Alberto Fernández: esto para dominios pequeños no sería necesario, con un Excel y tal podríamos perfectamente apañarnos, pero para dominios medianos que tengan 10-20K Urls… os habéis planteado algún tipo de plan que permita la recursividad del uso de la herramienta para una agencia.
Safecont: para un dominio que tenga 20K URLs la cuestión es que las horas que tu cobras de consultoría (50€ o 100€ o lo que cobre cada uno) si tienes que trabajar 50K URLs y con esto solo tienes que trabajar 5 horas… el resto es margen para ti…
Safecont: por cierto, no hemos comentado nada de lo que va a costar… la web ya está online, ya hemos quitado la parte beta y se puede visitar. Va por paquetes, paquetes que van por número de URLs que puedes analizar y hay un límite por número de dominios. Cada paquete te va a permitir X dominios hasta que gastes las URLs. Hay un paquete agencia que te va a permitir trabajar muchos dominios… no sé si te he entendido bien la pregunta o si va por ahí.
Alberto Fernández: sí, iba por las dos partes, una por esa parte agencia de un mismo dominio, y otra por un mismo dominio al que atacas recursivamente y poder ir viendo esa mejora.
Safecont: a su vez vas a tener créditos, si te quedas sin ellos vas a poder comprarlos (1 crédito – 1 URL). Si te hace falta analizar 2000 URLs más, pues las compras al mismo precio que has pagado en el paquete.
Safecont: Una cosa que vemos bastante buena (que lo hemos hecho tratando de ser lo más honestos posible) es que Safecont no tiene una cuota mensual, facturamos por cada crawleo y cada análisis que haces. Entonces, hago un análisis, ya sabes la foto de todo el dominio y sabes sus problemas… ¿por qué lo hacemos así? Porque es muy difícil que unos arreglos o unas soluciones que tienes que implementar como estas las hagas en poco tiempo… hay gente que funciona por ejemplo por proyectos trimestrales, entonces el tiempo medio de implementar todo esto puede ser de un mes, dos, tres… entonces para qué pagar una herramienta mensual cuando vas a tardar tres meses en hacer los cambios… no nos parecía honesto. Tú haces una foto, solucionas lo que tengas que solucionar, y luego te vas a ver si eso es eficiente, si te va a servir, si sigues en peligro… y sacas otra foto. Entonces pagarás por cada análisis que hagas. De todos modos iremos viendo el feedback de los clientes… y si es necesario realizar algún cambio.

Además, hoy hemos sabido que los dominios serán dominios activos, es decir, que podremos consumir las 5000 URLs analizando 10 dominios de 500. Con esto, particularmente pienso que el precio es bastante más asequible para cierto tipo de proyectos.
7. ¿Cómo conseguir una beta?
Otro asistente: ¿para conseguir la beta? Porque a mí esto me parece muy bien pero yo ahora voy a la agencia y le digo: hay una herramienta que… querrán probarla.
Safecont: hasta ahora nuestra web era una simple plataforma para pedir betas, con tu nombre, email y dominio. A partir de ahora no se puede, pero lógicamente si alguien quiere probarlo pues simplemente contacta con nosotros y… oye mira tengo este dominio, me gustaría hacer una prueba de la herramienta…
Safecont: también va a depender del dominio. Cuando abrimos las betas hubo gente que nos mandó directamente una página en HTML y ya está para analizar, y yo creo que no tiene ni contenido, ni duplicado ni nada… así que mientras sean cosas que puedas sacarle un poco más de partido para que sea un poco más visual, sin problema. Nos lo podéis escribir por Twitter o al email de la web, porque estaban llegando recurrentemente betas…
8. ¿Cuál es la limitación de URLs en la betas?
Otro asistente: ¿las betas con qué limitación de URLs las habéis metido?
Safecont: depende del dominio que nos hayan mandado. Han sido pequeñas, de 500 a 2500 URLs en algún caso particular. Generalmente hacemos una ponderación pero te tienes que hacer a la idea porque te puede dar un scoring pero solo sobre las URLs que haya visto, pero por lo menos para que se veas más o menos cómo funciona el sistema. Nos podéis escribir…
9. ¿Safecont solo está disponible en español?
Otro asistente: ¿el tema del análisis semántico lo hacéis solo en español?
Safecont: No, es multidioma, funciona en todos los idiomas porque la manera de analizarlo es completamente diferente al word to word.
Safecont: cuando empezamos con el proceso de desarrollo valoramos un montón de opciones, algoritmos, trabajar generando diccionarios por idioma… lo que pasa es que en coste es inviable y al final funciona mucho peor. Esto es matemáticas, el idioma en el que estamos da igual porque analiza un volumen grande del contexto y saca ciertas fórmulas que son comunes, entonces a nosotros nos da igual si es español, francés, italiano… nos da lo mismo. No lo hemos probado nada más que en español, catalán, francés, italiano e inglés.
Safecont: y en filipino también. Y ya es bastante. Te decía que había un dibujo muy parecido al otro…
Y ahora… ¿Alguna duda sobre Safecont? Cualquier comentarios será bienvenido y si son dudas y os las puedo contestar, genial. Si no puedo, seguro que alguno de los integrantes de Safecont me permite contestaros.
¡Hasta la próxima!