
Post anterior
¿Qué es Machine Learning? Google Machine Learning EngineDe forma general en un proyecto web podemos tener todos estos tipos de URLs.
- URLs totales
- URLs rastreables
- URLs rastreadas:
- URLs indexables: las URLs que por sus características a nivel de código y estrategia pueden ser potencialmente indexadas por un buscador.
- URLs indexadas: las URLs que un determinado buscador incorpora a sus índices.
- URLs posicionadas:
- URLs linkadas: las que reciben links, ya sean de forma interna desde otras URLs de nuestra web, o de forma externa en otras webs.
- URLs importantes: aquellas que son relevantes a nivel estratégico, tráfico, ventas, etc…
Para comenzar a trabajar las URLs de un sitio web es necesario saber obtenerlas y clasificarlas correctamente, y un buen comienzo suele ser a través de crawlers (rastreadores) y otros programas existentes, algunos de los cuales son gratuitos y uso libre. Vamos por partes…
URLs totales
La totalidad de URLs que puede tener internamente un proyecto.
Lo primero al trabajar en SEO, es necesario conocer el número total de URLs de nuestro proyecto, una cifra que se puede obtener fácilmente:
- descargando todos los logs por FTP y cargarlos en herramientas como SEOlyzer, Screaming Frog log Analyzer, FandangoSEO…
- extrayendo todas las URLs con un crawler: Screaming Frog, Sitebulb, Xenu, FandangoSEO…
- extrayendo todas las URLs que nos indique Analytics como páginas de destino de cualquier tipo de tráfico
- extrayendo el informe de Search Console con las páginas del informe de rendimiento
- extrayendo datos de cualquier otra herramienta que rastree y guarde dicha información (Yandex Metrika, Bing webmaster tools, etc…)
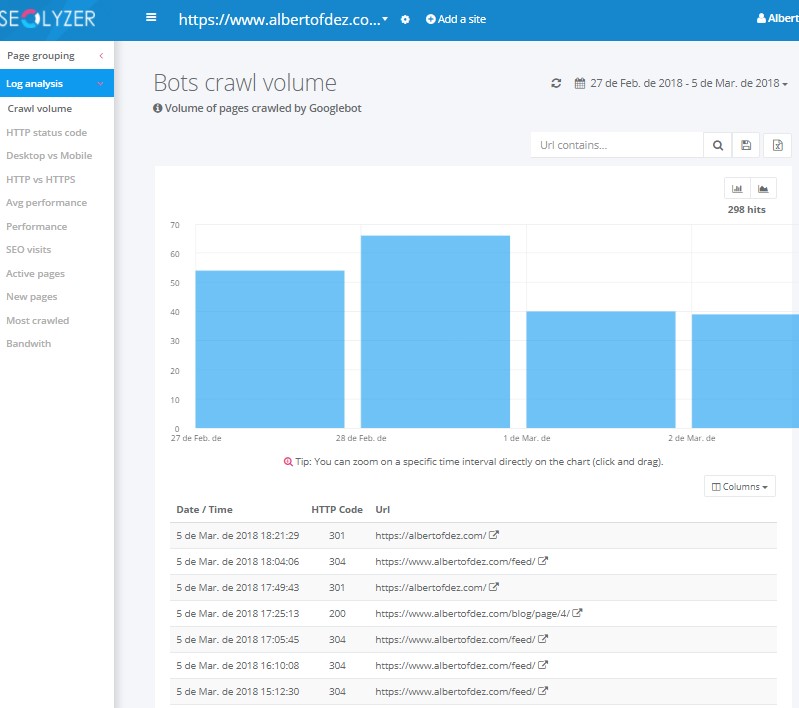
URLs rastreables y no rastreables
Las URLs rastreables son aquellas a las cuáles podría llegar un determinado rastreador o crawler.
A continuación, por ejemplo con Screaming Frog podemos llevar a cabo un crawleo para conocer a qué URLs llega Google a través de nuestra web. Cruzando ambos listados en excel (utilizando la opción de eliminar duplicados) conseguiremos el listado completo de URLs de la web.

Generalmente para listar ambos tipos me es más fácil siempre comenzar por las no rastreables, que podemos intuir en los directorios y extensiones de dominio bloqueadas en el archivo robots.txt y en el fichero oculto en la raíz (habitualmente) de nuestro FTP llamado .htaccess (servidores linux) o en web.config en servidores Windows. Además los crawlers te las suelen marcar en sus informes como “bloqueadas”.

URLs rastreadas
Dentro de las URLs rastreables, podemos diferenciar entre las que han sido rastreadas y las que no. En general, suelo considerar que una URL ha sido rastreada cuando el bot de Google ha pasado por ella durante los últimos 90 días, lo que podemos descubrir filtrando los logs por fecha.
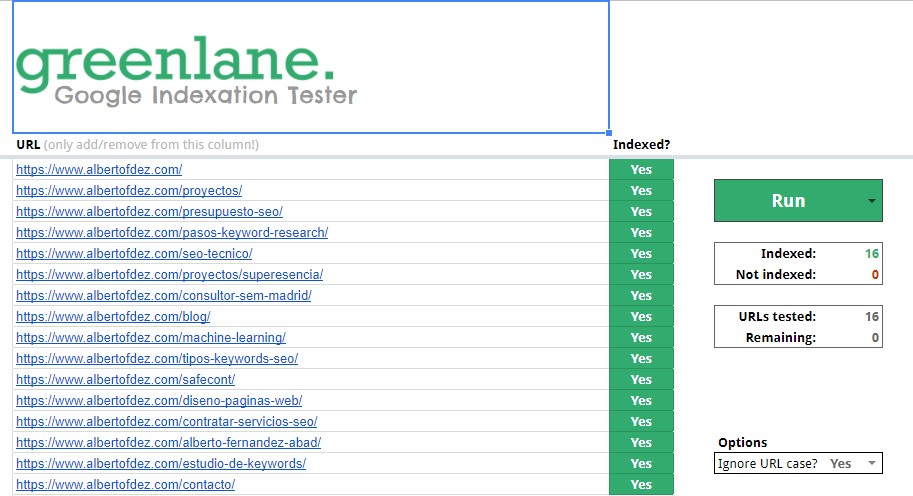
URLs indexables
A su vez, podemos distinguir entre indexadas y no indexadas. Esta tarea la podemos llevar a cabo con programas como URL Profiler (con proxys) o Greenlane (par pocas URLs está bien). Lo normal es que las URLs no rastreables no estén indexadas (se supone que lo hacemos a propósito por estrategia tras generar bien las configuraciones para robots en código y servidor). Por lo tanto, aquellas que sí lo estén deben ser revisadas para conocer el motivo: ¿error? ¿despiste? ¿Google hace lo que le apetece? ¿La quiero así por lo que sea? …
URLs indexadas
Las URLs indexadas suelen ser un número inferior a las rastreadas, dado que omitimos URLs canonicalizadas, con x-robots o metaetiqueta noindex y otros errores como duplicidades que los buscadores tiendan a obviar indexar.
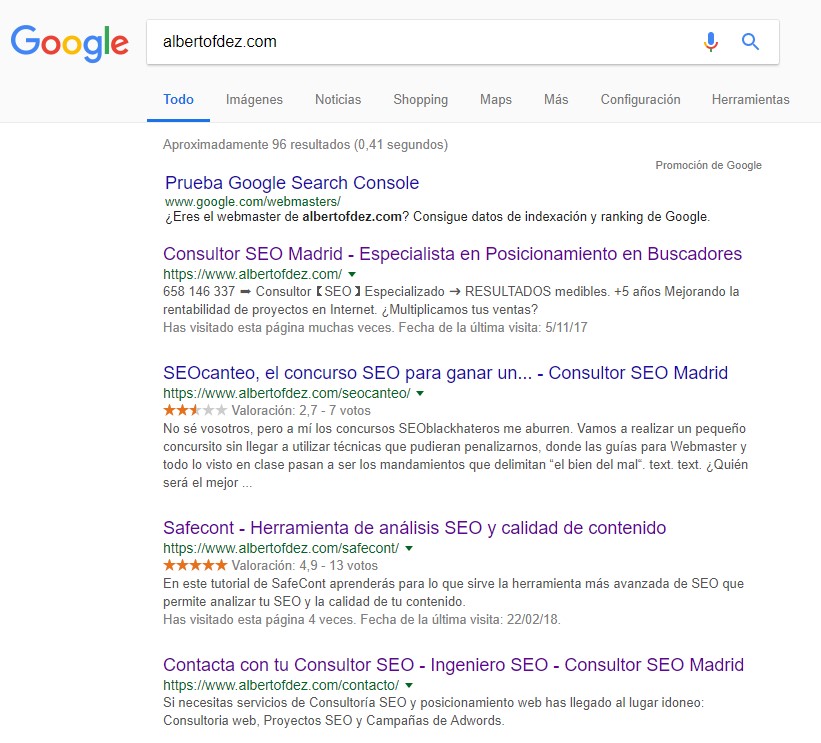
URLs posicionadas
URLs que tienen visibilidad dentro de las SERPs por uno o más términos de búsqueda.
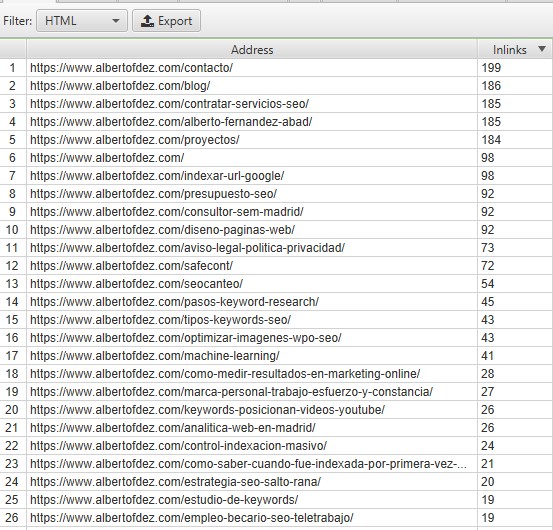
URLs linkadas
Las que reciben links, ya sean de forma interna desde otras URLs de nuestra web, o de forma externa en otras webs.

URLs importantes
Aquellas que son relevantes a nivel estratégico, tráfico, ventas, etc…
¿He olvidado alguna? Comenta y completamos 😉